Redis高级篇
Redis持久化
RDB(RedisDatabase)
RDB 会在指定的时间间隔(比如每 5 分钟)对 Redis 的内存数据进行一次“拍照”,生成一个二进制文件(dump.rdb)。这个文件可以自己设置名称,默认为dump.rdb.这个文件包含了当时的所有数据状态。
如果 Redis 崩溃了,重启时会加载最近的dump.rdb来恢复数据。
如果使用命令save可以直接保存rdb文件
每次启动Redis的时候Redis就会访问这个rdb文件来获取以前的数据
每次关闭Redis服务端的时候都会生成一个新的dump.rdb
文件就在这里
如果只是关机的时候使用,万一什么时候Redis宕机了,就无法恢复数据了,这时候得用间隔保存了,这时候只需要打开Redis配置文件,修改如下字段

# save ""表示注释掉了 Redis 的默认 RDB 持久化策略(即禁用默认的自动快照生成)。
下面的意思是900秒内有1次操作就保存一次,300秒内10次操作就自动保存一次,60秒内有10000次操作就保存一次.
fork 子进程:Redis 调用 fork() 创建一个子进程,子进程与主进程共享内存数据。
COW(Copy-On-Write):
- 子进程开始快照操作时,主进程仍可处理客户端请求并修改数据。
- 当主进程修改某个数据页时,操作系统会将该页复制一份(写时复制),子进程看到的仍是修改前的数据。
- 子进程将所有数据页写入磁盘生成
.rdb文件,而主进程不影响快照的一致性。
COW有缺点就是,如果我的Redis已经占用了很高的内存,此时我要修改的数据也很多,复制的数据非常多会导致内存溢出
并且修改次数多,导致复制次数也多,开销也很大
修改次数少的时候如果宕机就会导致大部分数据丢失
AOF(Append-Only File)
AOF则是记录每一次操作Redis的命令,把命令记录在磁盘中,如果后面需要恢复就再执行一次所有Redis命令,下面的就是AOF文件
只有修改了redis.conf中的如下文件后才能使用
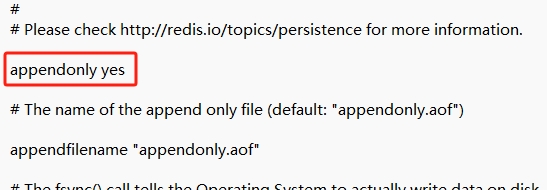
有如下三种记录频率

第一个是每写一次命令,执行完后就写入磁盘,然后返回信息,这样就很慢了,和直接操作数据库没有区别,第二个方法是隔了一秒后进行,实现了异步处理,顶多丢失1秒的数据,最后一种由操作系统判断什么时候写回磁盘,推荐使用第二种.

下面是AOF文件中的内容
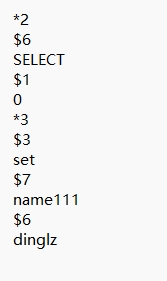
如果我写三个如下命令
|
|
这样直接写入aof文件会比较占内存,可以使用如下命令来重写AOF文件
|
|
重写后的文件如下
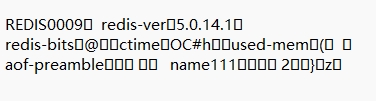
直接就看不懂了,但是这样确实简化了AOF文件,不用连续设置三次才得到最终数据.
|
|
可以看到这个命令甚至是在后台执行的
通常情况下是两种持久化机制一起使用,可以保证数据的稳定性
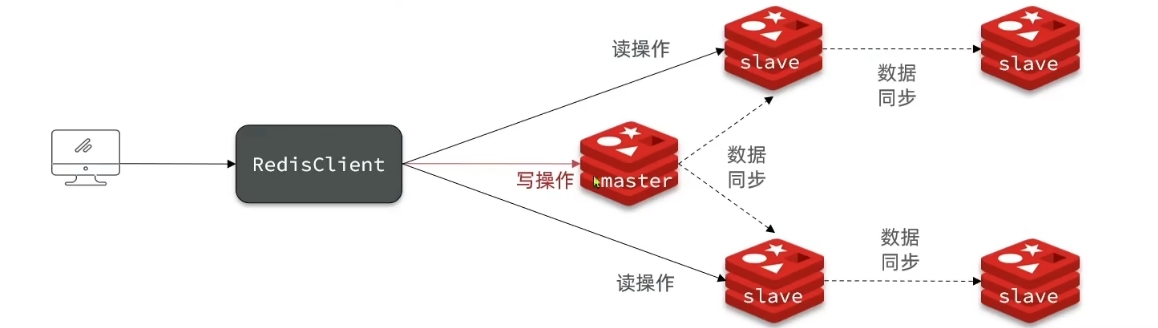
Redis主从同步
主从同步示例要三个Redis,我们可以使用windows本地复制三个Redis文件,然后修改配置文件,端口号6379,6380,6381,或者直接用docker,pull下redis的最新版本,然后创建三个实例.
分别启动三个Redis的服务端,然后再Redis-cli的6380上输入如下名令
|
|
意思是Redis6380要成为6379的从节点
也可以使用如下命令
|
|
这时候6380就是6379的从节点了
当我们在6379上使用set命令
|
|
那么从节点上也可以看到被修改了
|
|
这就实现了主从同步
全量同步
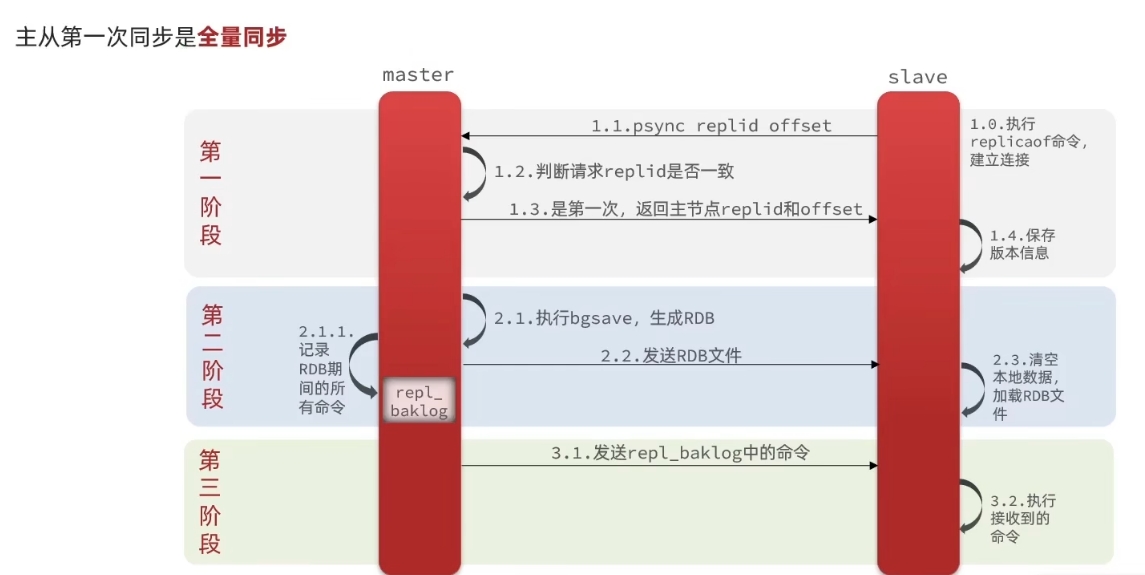
在我们输入slaveof host port之后,slave向master发送了自己的replid和offset,id和master肯定不一样,这时候就告知master这时候得做全量同步,清空slave本地缓存,把master生成的RDB发给slave进行数据同步.
并且在建立主从关系后,master会把自己的命令都交给slave去做数据同步,增量同步.
增量同步
repl_baklog是记录了RDB期间的所有命令的一个文件,是环状读写的,每次做增量同步的时候slave都会发送自己的offset,master在自己的repl_baklog表中查找offset,如果找到的话就把offset后面的数据交给master.下图红绿交接就是offset
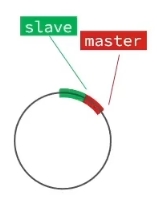
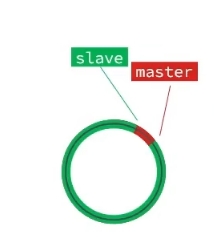
如果slave宕机了,而且时间还挺长,master写repl_baklog文件已经覆盖了offset,那此时只能做一个全量同步.
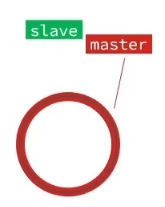
可以从以下几个方面来优化Redis主从就集群:
-
在master中配置repl-diskless-syncyes启用无磁盘复制,避免全量同步时的磁盘IO。
-
Redis单节点上的内存占用不要太大,减少RDB导致的过多磁盘IO
-
适当提高repl baklog的大小,发现slave宕机时尽快实现故障恢复,尽可能避免全量同步限制一个master上的slave节点数量,如果实在是太多slave,则可以采用主-从-从链式结构,减少master压力,可以直接从其他slave上直接读取数据,而不是都找master
哨兵模式
哨兵的工作原理
Redis的哨兵(Sentinel)是一个监控和故障转移系统,用于管理Redis主从复制架构中的高可用性。它在Redis 2.8版本中被引入,主要目的是解决当主节点出现故障时,如何自动完成故障发现和故障转移的问题。以下是关于Redis哨兵的一些
哨兵每一秒广播发送一次ping命令,告诉所有节点,自己没有宕机
如果某个节点在指定时间内没有响应,则会被标记为“主观下线”。如果主节点被标记为主观下线,哨兵会询问其他哨兵实例,根据多数哨兵的意见决定是否将其标记为“客观下线”。
客观下线后就会触发主从交换,选出一个offset最大的slave,向其发送slaveof no one,让其成为master节点,然后强制修改原主节点的配置文件,让那个redis slave of新的master,然后让所有节点都执行slaveof新master.