面试八股/场景2.0
介绍一下RDB和AOF
Redis 是一个基于内存的数据库,为了防止服务器宕机导致数据丢失,Redis 提供了两种主要的持久化机制:RDB (Redis Database) 和 AOF (Append Only File)。
这两者分别代表了两种不同的思路:快照(Snapshotting) 和 日志(Logging)。
1. RDB (Redis Database) —— 快照模式
RDB 是 Redis 默认的持久化方式。它会在指定的时间间隔内,将内存中的数据集快照写入磁盘。
工作原理
-
触发方式: 可以通过配置文件(如
save 900 1,表示900秒内有1个key变动则触发)自动触发,也可以手动执行SAVE或BGSAVE命令。 -
核心流程(BGSAVE):
-
Redis 主进程 fork 一个子进程。
-
子进程共享主进程的内存数据(利用操作系统的 Copy-on-Write / 写时复制 技术)。
-
子进程将数据写入到一个临时的 RDB 文件中。
-
写入完成后,用新文件替换旧的 RDB 文件。
-
✅ 优点
-
恢复速度快: RDB 是一个紧凑的二进制文件,非常适合用于灾难恢复和备份。Redis 加载 RDB 文件恢复数据的速度远快于 AOF。
-
文件体积小: 相比 AOF,RDB 文件更小,节省磁盘空间。
-
性能影响小: 父进程在
fork子进程后继续处理请求,持久化工作由子进程完成,最大化了 Redis 的性能。
❌ 缺点
-
数据丢失风险较高: RDB 是间隔执行的(例如每5分钟一次)。如果 Redis 在两次快照之间宕机,这期间产生的数据将会丢失。
-
大数据集下的停顿: 当数据集非常大(如几十 GB)时,
fork子进程的操作可能会比较耗时,导致 Redis 主进程出现毫秒级甚至秒级的阻塞。
2. AOF (Append Only File) —— 日志模式
AOF 记录了服务器接收到的每一个写操作(查询操作不记录)。服务器启动时,通过重新执行这些命令来还原数据。
工作原理
-
命令追加: 所有的写命令会先追加到 AOF 缓冲区。
-
同步策略(fsync): 根据配置将缓冲区内容同步到磁盘:
-
appendfsync always:每次写操作都同步(最安全,但性能最差)。 -
appendfsync everysec:每秒同步一次(默认推荐,兼顾性能与安全)。 -
appendfsync no:由操作系统决定何时同步(性能最好,但不可控)。
-
-
AOF 重写(Rewrite): 随着时间推移,AOF 文件会越来越大(例如:
SET a 1,SET a 2其实最终只是a=2)。Redis 会在后台对 AOF 文件进行重写,只保留恢复当前数据所需的最小命令集。
✅ 优点
-
数据安全性高: 使用
everysec策略,最坏情况下也只会丢失 1 秒的数据。 -
可读性强: AOF 文件是纯文本格式,如果误执行了
FLUSHALL,只要 AOF 文件未被重写,可以手动删掉文件末尾的该命令来挽救数据。
❌ 缺点
-
文件体积大: 记录所有写命令,导致 AOF 文件通常比 RDB 文件大得多。
-
恢复速度慢: 恢复数据时需要“重放”所有命令,速度比加载 RDB 二进制快照要慢。
-
写性能稍低: 根据 fsync 策略,AOF 对写性能有一定影响(通常
everysec影响很小)。
3. RDB vs AOF 核心对比
| 特性 | RDB (快照) | AOF (日志) |
|---|---|---|
| 数据安全性 | 较低 (可能丢失最后几分钟数据) | 高 (默认通常只丢1秒) |
| 恢复速度 | 非常快 | 较慢 (需重放命令) |
| 文件体积 | 小 (二进制压缩) | 大 (文本记录) |
| 资源消耗 | CPU 高 (Fork 过程), I/O 低 | CPU 低, I/O 高 (持续追加) |
| 启动优先级 | 低 (若开启 AOF,优先加载 AOF) | 高 (因为数据更全) |
Redis 是一个基于内存的数据库,为了防止服务器宕机导致数据丢失,Redis 提供了两种主要的持久化机制:RDB (Redis Database) 和 AOF (Append Only File)。
这两者分别代表了两种不同的思路:快照(Snapshotting) 和 日志(Logging)。
以下是两者的详细对比与解析:
1. RDB (Redis Database) —— 快照模式
RDB 是 Redis 默认的持久化方式。它会在指定的时间间隔内,将内存中的数据集快照写入磁盘。
工作原理
-
触发方式: 可以通过配置文件(如
save 900 1,表示900秒内有1个key变动则触发)自动触发,也可以手动执行SAVE或BGSAVE命令。 -
核心流程(BGSAVE):
-
Redis 主进程 fork 一个子进程。
-
子进程共享主进程的内存数据(利用操作系统的 Copy-on-Write / 写时复制 技术)。
-
子进程将数据写入到一个临时的 RDB 文件中。
-
写入完成后,用新文件替换旧的 RDB 文件。
-
✅ 优点
-
恢复速度快: RDB 是一个紧凑的二进制文件,非常适合用于灾难恢复和备份。Redis 加载 RDB 文件恢复数据的速度远快于 AOF。
-
文件体积小: 相比 AOF,RDB 文件更小,节省磁盘空间。
-
性能影响小: 父进程在
fork子进程后继续处理请求,持久化工作由子进程完成,最大化了 Redis 的性能。
❌ 缺点
-
数据丢失风险较高: RDB 是间隔执行的(例如每5分钟一次)。如果 Redis 在两次快照之间宕机,这期间产生的数据将会丢失。
-
大数据集下的停顿: 当数据集非常大(如几十 GB)时,
fork子进程的操作可能会比较耗时,导致 Redis 主进程出现毫秒级甚至秒级的阻塞。
2. AOF (Append Only File) —— 日志模式
AOF 记录了服务器接收到的每一个写操作(查询操作不记录)。服务器启动时,通过重新执行这些命令来还原数据。
工作原理
-
命令追加: 所有的写命令会先追加到 AOF 缓冲区。
-
同步策略(fsync): 根据配置将缓冲区内容同步到磁盘:
-
appendfsync always:每次写操作都同步(最安全,但性能最差)。 -
appendfsync everysec:每秒同步一次(默认推荐,兼顾性能与安全)。 -
appendfsync no:由操作系统决定何时同步(性能最好,但不可控)。
-
-
AOF 重写(Rewrite): 随着时间推移,AOF 文件会越来越大(例如:
SET a 1,SET a 2其实最终只是a=2)。Redis 会在后台对 AOF 文件进行重写,只保留恢复当前数据所需的最小命令集。
✅ 优点
-
数据安全性高: 使用
everysec策略,最坏情况下也只会丢失 1 秒的数据。 -
可读性强: AOF 文件是纯文本格式,如果误执行了
FLUSHALL,只要 AOF 文件未被重写,可以手动删掉文件末尾的该命令来挽救数据。
❌ 缺点
-
文件体积大: 记录所有写命令,导致 AOF 文件通常比 RDB 文件大得多。
-
恢复速度慢: 恢复数据时需要“重放”所有命令,速度比加载 RDB 二进制快照要慢。
-
写性能稍低: 根据 fsync 策略,AOF 对写性能有一定影响(通常
everysec影响很小)。
3. RDB vs AOF 核心对比
| 特性 | RDB (快照) | AOF (日志) |
|---|---|---|
| 数据安全性 | 较低 (可能丢失最后几分钟数据) | 高 (默认通常只丢1秒) |
| 恢复速度 | 非常快 | 较慢 (需重放命令) |
| 文件体积 | 小 (二进制压缩) | 大 (文本记录) |
| 资源消耗 | CPU 高 (Fork 过程), I/O 低 | CPU 低, I/O 高 (持续追加) |
| 启动优先级 | 低 (若开启 AOF,优先加载 AOF) | 高 (因为数据更全) |
4. 最佳实践:混合持久化 (Redis 4.0+)
在 Redis 4.0 之前,通常建议同时开启 RDB(做备份)和 AOF(保数据)。
Redis 4.0 引入了混合持久化(Hybrid Persistence):
这是目前的推荐配置。它结合了 RDB 和 AOF 的优点:
-
机制: 在进行 AOF 重写时,Redis 会将当前内存的数据以 RDB 格式 写入 AOF 文件的开头,随后的增量写操作继续以 AOF 文本格式 追加到文件末尾。
-
结果: AOF 文件前半部分是 RDB(加载快、体积小),后半部分是增量日志(数据全)。
-
效果: 既保证了快速启动(加载 RDB 部分),又保证了数据不丢失(加载 AOF 增量部分)。
进程和线程的区别
用一句话概括:进程是资源分配的最小单位,线程是 CPU 调度的最小单位。
核心区别详解
1. 资源的拥有权(Resource Ownership)
-
进程: 拥有独立的内存空间(代码段、数据段、堆等)和系统资源(文件描述符等)。不同进程之间的资源是隔离的。
-
线程: 线程本身不拥有系统资源,只拥有很少的运行中必不可少的资源(如程序计数器、栈、寄存器)。同一进程内的所有线程共享该进程的内存空间(堆、全局变量)和文件资源。
2. 调度与开销(Overhead & Switching)
-
进程: 切换成本高。当操作系统切换进程时,需要保存当前进程的上下文(内存页表、CPU 状态等)并加载新进程的上下文,这会导致 CPU 缓存失效,开销较大。
-
线程: 切换成本低。同一进程内的线程切换,不需要切换内存页表,只需要保存和恢复少量的寄存器内容和栈信息,速度很快。
3. 通信方式(Communication)
-
进程间通信 (IPC): 困难。因为内存隔离,进程间需要通过特殊机制通信,如:管道 (Pipe)、消息队列、共享内存、信号量、Socket 等。
-
线程间通信: 容易。因为共享内存(堆),线程之间可以直接读写同一变量来进行通信。
- 注意: 虽然通信容易,但带来了**线程安全(同步)**问题,需要使用锁(Lock)或 CAS 等机制来防止数据错乱。
4. 健壮性与隔离性(Stability)
-
进程: 健壮性强。一个进程崩溃通常不会影响其他进程(因为内存是隔离的)。例如:Chrome 浏览器的一个标签页(进程)崩了,通常不会导致整个浏览器崩溃。
-
线程: 健壮性弱。一个线程出现致命错误(如非法内存访问),可能会导致整个进程崩溃,进而导致该进程内的所有线程都挂掉。
对比总结表
| 维度 | 进程 (Process) | 线程 (Thread) |
|---|---|---|
| 本质 | 资源分配的最小单位 | CPU 调度的最小单位 |
| 内存空间 | 独立(互不干扰) | 共享(同一进程内) |
| 切换开销 | 大 (涉及虚拟内存、页表切换) | 小 (不涉及内存地址空间切换) |
| 通信难度 | 难 (IPC:管道、Socket等) | 易 (直接读写共享变量) |
| 稳定性 | 进程间隔离,一个崩了不影响其他 | 一个线程崩了可能搞挂整个进程 |
| 并发性 | 也可以并发,但资源消耗大 | 并发性高,资源消耗小 |
Redis的内存淘汰机制
当 Redis 的内存使用量达到在 redis.conf 中配置的 maxmemory 上限时,为了能继续接收新的写入请求,Redis 必须根据配置的策略删除一部分数据。这就是 Redis 的内存淘汰机制。
Redis 提供了 8 种 淘汰策略(Redis 4.0 之后),我们可以从**“淘汰范围”和“淘汰算法”**两个维度来理解。
1. 两个核心维度
在记忆这些策略之前,先理解两个概念,这样就不需要死记硬背了:
-
淘汰范围(也就是“去哪里选”):
-
allkeys:从所有键中筛选(不管有没有设置过期时间)。通常用于把 Redis 当纯缓存用的场景。 -
volatile:只从**设置了过期时间(TTL)**的键中筛选。通常用于把 Redis 当数据库用,同时又想缓存一部分临时数据的场景。
-
-
淘汰算法(也就是“怎么选”):
-
LRU (Least Recently Used):最近最少使用。
-
LFU (Least Frequently Used):最不经常使用(Redis 4.0+)。
-
Random:随机。
-
TTL:快过期的。
-
Redis 的 LRU 是真的 LRU 吗?
不是。 Redis 使用的是近似 LRU 算法(Approximated LRU)。
-
原因: 严格的 LRU 需要维护一个巨大的双向链表,每访问一次 key 就要移动节点,这非常消耗内存且影响性能。
-
实现: Redis 采用随机采样的方式。当需要淘汰时,它随机抽取 N 个 key(默认 5 个,由
maxmemory-samples配置),然后淘汰这 N 个里面最久没被访问的那一个。 -
效果: 虽然是近似的,但在 Redis 3.0 优化后,效果已经非常接近严格 LRU 了。
Redis的各种淘汰策略
| 策略前缀 | 策略后缀 (算法) | 含义 | 适用场景 |
|---|---|---|---|
| noeviction | - | 不淘汰,写请求报错 | 纯数据存储,数据不能丢 |
| allkeys | -lru | 所有Key + 最近最少使用 | 通用缓存 (推荐) |
| allkeys | -lfu | 所有Key + 最不经常使用 | 即使最近被访问过,总体访问频率低也被淘汰 |
| allkeys | -random | 所有Key + 随机 | 极少使用 |
| volatile | -lru | 过期Key + 最近最少使用 | 混合存储,只淘汰缓存部分 |
| volatile | -lfu | 过期Key + 最不经常使用 | 同上 |
| volatile | -random | 过期Key + 随机 | 极少使用 |
| volatile | -ttl | 过期Key + 剩余时间最短 | 让快过期的先走 |
Java的双亲委派模型是什么?
双亲委派模型(Parent Delegation Model) 是 Java 类加载机制的核心设计思想。
虽然名字听起来有点高大上(甚至有点拗口),但它的核心逻辑非常简单,用一句话概括就是:“这也是为了你好:有事儿先找你爹,你爹搞不定你再自己来。”
下面我从结构、流程、作用和例外四个方面为你拆解。
1. 谁是“双亲”?(类加载器的层级)
在 Java 中,类加载器(ClassLoader)是有层级关系的。并不是真的有两个亲戚(“双亲”这个翻译其实有点误导,它指的是 Parent,即父级)。
主要的类加载器有三层:
-
启动类加载器 (Bootstrap ClassLoader)
-
地位: 老祖宗,最顶层。
-
职责: 负责加载 Java 的核心类库(如
java.lang.String,rt.jar等)。它是用 C++ 写的,在 Java 代码里拿不到它的引用(也就是null)。 -
它负责加载 Java 运行时环境(JRE)中最核心的库。这些类位于
$JAVA_HOME/jre/lib目录下,通常打包在rt.jar(Runtime Jar) 中。💡 具体例子: 只要是
java.*开头的几乎都是它加载的。-
基础类型包装类:
java.lang.Integer,java.lang.Double,java.lang.String -
集合框架:
java.util.ArrayList,java.util.HashMap,java.util.HashSet -
IO 流:
java.io.File,java.io.FileInputStream -
并发包:
java.util.concurrent.ConcurrentHashMap -
线程:
java.lang.Thread
🧐 现象: 如果你在代码里打印
String.class.getClassLoader(),你会得到null。这不是因为没加载,而是因为 Bootstrap 是用 C++ 写的,Java 代码无法获取它的引用。 -
-
-
扩展类加载器 (Extension ClassLoader)
-
地位: 中间层。
-
职责: 负责加载 Java 的扩展库(
JAVA_HOME/lib/ext目录下的 jar 包)。 -
它负责加载
$JAVA_HOME/jre/lib/ext目录下的类库,或者被java.ext.dirs系统变量所指定的路径。它是对 Java 核心功能的补充。💡 具体例子: 这些类通常平时用得少一点,多涉及一些加密、特殊网络协议或 XML 解析等。
-
加密库:
com.sun.crypto.provider.SunJCE(Java 加密扩展,做 AES/DES 加密时会用到) -
DNS 相关:
sun.net.spi.nameservice.dns.DNSNameService(某些 JDK 版本下的 DNS 解析服务) -
JavaScript 引擎:
jdk.nashorn.api.scripting.NashornScriptEngine(Java 8 中内置的 JS 引擎)
-
-
-
应用程序类加载器 (Application ClassLoader)
-
地位: 最底层(系统默认)。
-
职责: 负责加载我们自己写的代码(
ClassPath下的类)和第三方 Jar 包。 -
这是我们接触最多的加载器。它负责加载
CLASSPATH环境变量或系统属性java.class.path指定的类库。💡 具体例子: 凡是你自己在工程里写的,或者在
pom.xml/build.gradle里引用的,都归它管。-
你写的业务代码:
-
com.example.project.UserController -
com.example.project.MyUtils -
你的
Main启动类
-
-
第三方开源框架(Maven 依赖):
-
Spring 全家桶:
org.springframework.boot.SpringApplication,org.springframework.context.ApplicationContext -
数据库驱动:
com.mysql.cj.jdbc.Driver(注意:虽然 Driver 接口是核心的,但 MySQL 的实现类是 App 加载的) -
中间件客户端:
org.apache.rocketmq.client.producer.DefaultMQProducer(RocketMQ),com.alibaba.dubbo.config.ApplicationConfig(Dubbo) -
工具类:
com.alibaba.fastjson.JSON,org.apache.commons.lang3.StringUtils
-
-
-
此外,还可以有自定义类加载器 (Custom ClassLoader),挂在应用程序类加载器下面。
2. 委派流程(怎么工作?)
当一个类加载器收到了类加载的请求时,它不会自己立即去加载,而是遵循以下步骤:
-
向上委托: 它会把这个请求委托给父类加载器去执行。
-
层层传递: 父类加载器如果还有父类,就继续向上委托,直到传到最顶层的 Bootstrap ClassLoader。
-
向下尝试:
-
Bootstrap 尝试加载,如果找到了(比如是
String),就直接返回。 -
如果 Bootstrap 没找到(也就是它管辖的范围里没有这个类),就告诉子类(Extension):“我搞不定,你来吧”。
-
Extension 尝试加载,如果没找到,再往下交给 Application。
-
Application 尝试加载,如果也没找到,就会抛出
ClassNotFoundException。
-
3. 为什么要这么设计?(核心作用)
双亲委派模型主要解决了两个大问题:
✅ 1. 安全性 (Security) —— 防止核心 API 被篡改
假设黑客写了一个恶意的类,名字也叫 java.lang.String,并且放在了你的 ClassPath 下。
如果没有双亲委派,系统就会加载这个恶意的 String 类,你的密码、数据全都会被黑客截获。 有了双亲委派: 系统在加载 String 时,会一直往上找,最终由 Bootstrap ClassLoader 加载了 JDK 自带的那个正版 String。黑客写的那个类永远没有机会被加载。
✅ 2. 避免重复加载 (Uniqueness)
Java 类在内存中的唯一性是由 “类加载器 + 类全名” 共同决定的。
如果同一个 System 类被两个不同的加载器各加载了一次,JVM 会认为它们是两个完全不同的类,这会导致类型转换异常,系统会乱套。
双亲委派保证了核心类永远只由顶层的加载器加载一次。
4. 什么时候需要打破双亲委派?
虽然双亲委派很好,但在某些特殊场景下,它反而成了阻碍,我们需要“打破”它(即:不让父类先加载,而是自己先加载,或者绕过父类)。
经典案例:
-
Tomcat (Web 容器):
-
Tomcat 上可能部署了两个 Web 应用,一个用 Spring 4,一个用 Spring 5。
-
如果用默认的双亲委派,Spring 类库只能加载一份,会导致冲突。
-
解决: Tomcat 自定义了类加载器,优先加载 Web 应用自己
WEB-INF/lib下的类,打破了“向上委托”的规则(先自己找,找不到再问爸爸)。
-
-
JDBC (SPI 机制):
-
Java 核心包提供了
java.sql.Driver接口(在 Bootstrap 层加载)。 -
但是具体的实现(如 MySQL 驱动)是第三方厂商提供的(在 ClassPath 下,由 App 层加载)。
-
这里出现了一个悖论:Bootstrap 层的代码需要去调用 App 层的代码。父加载器是看不到子加载器的类的。
-
解决: 使用 线程上下文类加载器 (Thread Context ClassLoader),让父级加载器“走后门”拿到子级加载器去加载类。
-
HashMap与ConcurentHashMap的区别
HashMap 和 ConcurrentHashMap (CHM) 的核心区别在于:线程安全性和底层实现机制
简单来说:
-
HashMap 是非线程安全的,性能极高,适合单线程。
-
ConcurrentHashMap 是线程安全的,高并发下性能依然优秀,适合多线程。
核心区别详解
① 线程安全性 (Thread Safety)
-
HashMap:
-
不安全。 如果多个线程同时写入 HashMap,可能会导致数据覆盖(Data Race)。
-
严重问题: 在 JDK 1.7 中,多线程并发扩容(Resize)时甚至会导致链表成环,造成
Infinite Loop(死循环),CPU 飙升 100%。虽然 JDK 1.8 修复了死循环问题,但依然会有数据丢失风险。
-
-
ConcurrentHashMap:
- 安全。 它是专门为并发设计的。内部使用了非常精妙的锁机制和 CAS 操作,保证了多线程下的数据一致性。
② 锁的粒度 (Locking Granularity) —— 性能的关键
-
HashMap: 没有锁。
-
Hashtable (反面教材): 使用
synchronized锁住整个 Map(一把大锁)。只要有一个线程在写,其他线程无论是读还是写都得排队,效率极低。 -
ConcurrentHashMap:
-
JDK 1.7: 使用 分段锁 (Segment Locking)。将数据分成一段一段(默认 16 段),每次只锁住被修改的那一段。
-
JDK 1.8 (优化): 抛弃了分段锁,采用 CAS +
synchronized。锁的粒度更细,只锁住哈希桶的头节点。这意味着只要两个线程操作的 Key 不在同一个桶(Hash冲突),它们就可以完全并行,互不干扰! -
能用无锁(CAS)解决的就用无锁,解决不了的再用锁(synchronized),而且锁本身也做了巨大的优化
-
1. CAS (Compare And Swap) —— 冲锋在前的“轻骑兵”
CAS 是一种乐观锁机制。它的核心思想是:“我认为没人跟我抢,所以我直接尝试更新。如果真的有人抢(比较失败),我再重试或放弃。”
在 JDK 1.8 的 CHM 中,CAS 主要用于无竞争场景和状态设置,它的速度非常快,因为它直接对应 CPU 的一条原子指令(cmpxchg)。
CAS 在哪里用?
-
插入新节点(最关键的路径): 当
put一个数据时,如果计算出的 Hash 槽位(Bucket)是空的(没有发生哈希冲突),CHM 不会加锁,而是直接用 CAS 尝试把新节点放入该位置。-
代码逻辑:
casTabAt(tab, i, null, new Node(...)) -
优势: 这种情况在哈希散列良好的情况下非常常见,完全避免了加锁的开销。
-
-
初始化数组: 在
initTable方法中,通过 CAS 修改sizeCtl变量(将其设为 -1),来抢占“初始化数组”的权利。只有一个线程能 CAS 成功,其他的线程会yield让出 CPU。 -
计数更新: 在
addCount方法中,利用类似LongAdder的机制(Cells数组),通过 CAS 累加元素的数量。
CAS 的潜在问题:
-
ABA 问题:(虽然在 CHM 的节点插入中通常不涉及,但在其他并发场景需注意)。
-
自旋开销: 如果竞争太激烈,CAS 一直失败重试(自旋),会白白浪费 CPU 资源。
2. Synchronized —— 坐镇后方的“重装卫士”
在 JDK 1.6 之前,synchronized 是重量级锁,性能很差。但在 JDK 1.8 中,它是经过武装牙齿的“新式重甲”。
Synchronized 在哪里用?
仅在发生哈希冲突时使用。
当 put 数据时,如果发现目标槽位已经有节点了(Hash 冲突),CAS 就搞不定了(因为要操作链表或红黑树,涉及多个指针的变动,CAS 很难保证原子性)。
此时,CHM 会用 synchronized 锁住该槽位的头节点。
底层实现深度对比 (JDK 1.7 vs JDK 1.8)
这是面试中最能体现深度的部分,重点关注 ConcurrentHashMap 的演进。
HashMap
-
JDK 1.7: 数组 + 链表。
-
JDK 1.8: 数组 + 链表 + 红黑树。当链表长度 > 8 且数组长度 > 64 时,链表会转为红黑树,将查询复杂度从 $O(n)$ 优化到 $O(\log n)$。
ConcurrentHashMap (进化史)
| 特性 | JDK 1.7 (分段锁) | JDK 1.8 (CAS + Synchronized) |
|---|---|---|
| 核心结构 | Segment 数组 + HashEntry 数组 + 链表 | Node 数组 + 链表 + 红黑树 |
| 锁机制 | ReentrantLock (Segment 继承自它) | CAS (乐观锁) + synchronized |
| 锁粒度 | 粗。锁住一个 Segment (默认含多个 Hash 桶) | 细。只锁住当前 Hash 桶的头节点 |
| 并发度 | 受限于 Segment 个数 (默认 16) | 理论上等于 Hash 桶的数量 (数组长度) |
| 读操作 | volatile 保证可见性,无锁 |
volatile 保证可见性,无锁 |
JDK 1.8 为什么要放弃分段锁?
-
内存占用: 每个 Segment 都要继承 ReentrantLock,通过 AQS 维护队列,内存开销大。
-
锁粒度不够细: 即使分了 16 段,依然可能存在多个线程竞争同一个段的情况。
-
效率提升: JDK 1.6 之后 JVM 对
synchronized做了大量优化(偏向锁、轻量级锁),在低竞争下性能已经非常好了,没必要维护复杂的 ReentrantLock。
3. 总结对比表
| 维度 | HashMap | ConcurrentHashMap |
|---|---|---|
| 线程安全 | ❌ 否 | ✅ 是 |
| Null Key/Value | ✅ 允许 | ❌ 不允许 |
| 原理 (JDK8) | 数组 + 链表 + 红黑树 | 数组 + 链表 + 红黑树 + CAS + synchronized |
| 扩容机制 | 新建数组 -> 迁移数据 | 能够支持多线程并发协助扩容 (这是 CHM 1.8 的黑科技) |
| 应用场景 | 局部变量、单线程环境 | 全局缓存、高并发环境 |
为什么要用synchronized去处理hash冲突
CAS 的“射程”只有 1 个变量 (One Word)
这是核心原因。 CAS 只能保证对“内存中某一个地址”的更新是原子的。
-
没有冲突时(put 到空槽位): 只需要把
Node放入数组的tab[i]位置。这就只涉及一个变量(数组的一个坑位)的修改。CAS(tab, i, null, newNode)-> 搞得定! ✅
-
有冲突时(链表/红黑树): 这就不是改一个变量的事了,这是一个复合操作(Compound Operation)。
-
场景一:链表追加 你需要先遍历链表找到最后一个节点
Tail,然后把Tail.next指向NewNode。 看似只改了Tail.next一个变量,但在并发环境下,你必须保证从你找到 Tail 到你修改 Tail 的这段时间里,Tail 没有被别人删掉,也没有别人在后面先插了一脚。如果要用 CAS 解决这个问题,必须极其复杂的自旋重试,代码复杂度指数级上升。 -
场景二:红黑树旋转 (最致命的) 红黑树插入节点后,为了保持平衡,可能需要变色和旋转。 一次旋转(左旋/右旋)往往涉及到 3 到 5 个指针的同时修改(父节点指向子节点、子节点指向孙节点、父节点指向新的子节点…)。 CAS 一次只能改 1 个指针,无法同时原子性地修改 3 个指针。 如果你用 3 次 CAS 分别去改,那在第 1 次和第 2 次之间,树的结构是断裂的。其他线程读到这个断裂的树,程序直接崩了。
-
结论: synchronized 锁住的是**“一段代码逻辑”(原子性范围大),而 CAS 锁住的是“一个变量”**(原子性范围小)。处理复杂数据结构变动,必须用大范围的锁。
Redis挂了RocketMQ挂了都怎么处理
Redis 挂了怎么处理?
Redis 挂了,最大的风险是大量流量瞬间击穿缓存,直接打到数据库(MySQL),导致数据库宕机,引发“缓存雪崩”。
1. 架构层面(事前:别让它挂)
生产环境绝对不能用单机版(Standalone)Redis。
-
哨兵模式 (Sentinel): 此时如果主节点挂了,哨兵会自动选举一个从节点变成主节点。业务层感知很小。
-
集群模式 (Cluster): 数据分片。某一个分片的主节点挂了,该分片的从节点上位。
2. 应用层面(事中:挂了怎么办)
这是开发最需要关心的。如果 Redis 真的全挂了,代码必须有降级策略。
-
方案 A:二级缓存(本地缓存)兜底
-
策略: 请求先查 Redis -> Redis 挂了/没数据 -> 查本地缓存 (如 Caffeine/Guava) -> 本地也没 -> 查数据库。
-
作用: 本地缓存虽然容量小,但能扛住短期的高热点流量,给数据库争取喘息时间。
-
-
方案 B:熔断与限流(Circuit Breaker & Rate Limiting)
-
工具: Sentinel (阿里), Hystrix, Resilience4j。
-
逻辑: 当监测到访问 Redis 的异常率飙升(比如连接超时),直接熔断 Redis 调用。
-
后续: 请求不再去连 Redis(防止卡死线程),而是直接限流访问数据库。比如平时 10000 QPS,Redis 挂了,限制只有 200 QPS 能打到数据库,剩下的请求直接报错或返回默认值。
-
目的: 保住数据库! 只要数据库还活着,服务就还有救;数据库挂了,整个系统就完了。
-
-
方案 C:服务降级
- 如果是非核心业务(比如“猜你喜欢”、“热搜榜”),Redis 挂了直接返回空数据或静态的默认数据,不要去查数据库。
3. 关于分布式锁
-
如果你的系统依赖 Redis 做分布式锁(Redisson),Redis 挂了会导致锁失效或无法加锁。
-
处理: 这种情况下通常需要业务报错(Fail Fast),或者降级为数据库乐观锁(Version字段),但并发性能会大打折扣。
MQ (消息队列) 挂了怎么处理?
MQ (如 RocketMQ, Kafka, RabbitMQ) 挂了,最大的风险是上下游解耦失败,导致核心链路断开(如下单成功了,但扣库存/发积分的消息发不出去了),或者数据丢失。
1. 架构层面(事前:别让它挂)
-
集群部署: 无论是 Kafka 还是 RocketMQ,都是主从/多副本机制。
-
多机房/多Broker: 确保一个 Broker 挂了,Producer 可以自动重连到其他 Broker 发送消息。
2. 应用层面(事中:生产者发不出去怎么办?)
这是最关键的。如果 MQ 彻底连不上了,生产者(Producer)必须有备选方案。
-
方案 A:本地消息表(Local Message Table)—— 最稳妥方案
-
原理: 既然 MQ 连不上,那就把消息写到本地数据库的一张表里(和业务数据在同一个事务中)。
-
流程:
-
开启数据库事务。
-
执行业务 SQL(如下单)。
-
执行插入 SQL:
INSERT INTO local_msg_table ... status='PENDING'。 -
提交事务。
-
-
恢复: 启动一个定时任务(Timer),轮询这张本地消息表,把状态是 ‘PENDING’ 的消息尝试重新发给 MQ。一旦发送成功,从表中删除或更新状态。
-
-
方案 B:写入本地磁盘/文件
-
原理: 如果数据库压力也很大,可以将消息内容追加写入服务器的本地日志文件。
-
恢复: 后续写个脚本读取日志文件,重新灌入 MQ。
-
-
方案 C:同步直连(极端降级)
-
如果业务允许,当 MQ 挂了,消费者(Consumer)提供一个 HTTP/RPC 接口。生产者发现 MQ 发送失败,直接调用消费者的 RPC 接口(将异步变同步)。
-
缺点: 失去了削峰填谷的作用,消费者可能扛不住压力。
-
3. 应用层面(事中:消费者收不到怎么办?)
-
积压处理: MQ 挂了期间,消息无法消费。等 MQ 恢复后,可能会有海量消息涌入。
-
策略: 消费者需要评估是否增加线程数,或者临时起一套只负责“搬运”的消费者,把消息快速落库,然后再慢慢处理,防止消费者被压垮。
介绍TiDB的计算与存储分离,和MySQL的区别是什么
一句话概括:TiDB 把“处理 SQL 的脑子”和“存数据的肚子”彻底分开了,中间通过网络(RPC)通信。
一、 TiDB 的计算与存储分离架构
TiDB 的架构主要由三大组件组成,完美体现了这种分离:
1. 计算层:TiDB Server(无状态的“大脑”)
-
职责: 负责接收客户端的 SQL 请求,进行 SQL 解析、语法检查、制定查询计划(Optimizer)、生成执行器。
-
特点: 它是无状态的(Stateless)。 它不存储任何实际的数据。
-
扩展性: 如果你发现 SQL 解析慢了,或者并发连接数太高了,只需要加几台 TiDB Server 机器就行,完全不需要进行数据迁移。
2. 存储层:TiKV(分布式的“肚子”)
-
职责: 负责存储真正的数据。底层是一个巨大的、分布式的、有序的 Key-Value Map。
-
实现: 内部使用 RocksDB 存储引擎。数据被切分成很多个 Region(默认 96MB),通过 Raft 协议(类似 Paxos)保证多副本一致性。
-
扩展性: 如果你发现硬盘满了,或者磁盘 I/O 扛不住了,只需要加几台 TiKV 机器,数据会自动均衡过去。
3. 调度层:PD (Placement Driver)(“总指挥”)
- 职责: 存储元数据(哪个 Key 在哪个 TiKV 上),负责给 TiDB Server 提供路由信息,同时指挥 TiKV 进行数据搬迁和负载均衡。
二、 TiDB 与 MySQL 的核心区别
我们将传统 MySQL(单机或主从架构)与 TiDB 进行深度对比:
| 维度 | MySQL (传统架构) | TiDB (存算分离架构) |
|---|---|---|
| 架构模式 | 紧耦合 (Monolithic) | 松耦合 (Microservices-like) |
| 进程结构 | SQL 解析器和 InnoDB 引擎在同一个进程 (mysqld) 中。 |
SQL 解析在 TiDB 进程,数据存储在 TiKV 进程,通常部署在不同机器上。 |
| 通信方式 | 内存函数调用 (Function Call),极快。 | 网络 RPC 调用 (gRPC),有网络延迟开销。 |
| 扩展能力 (Scaling) | 垂直扩展 (Vertical):买更好的 CPU/内存。 分库分表:需要中间件,运维极其痛苦。 |
水平扩展 (Horizontal):计算不足加 TiDB,存储不足加 TiKV,完全透明,业务无感知。 |
| 查询执行 | 数据在哪,计算就在哪。 | 分布式计算:TiDB 生成计划,分发给多个 TiKV 并行处理。 |
| 事务限制 | 受限于单机内存和磁盘,大事务容易导致主从延迟。 | 基于 Percolator 模型 (Google) 的两阶段提交 (2PC),支持跨行跨表分布式事务。 |
| 高可用 | 需依赖 MHA/Orchestrator,主从切换可能丢数据或需人工介入。 | 基于 Raft 协议,自动选主,强一致性,RPO = 0(数据不丢)。 |
为什么lua脚本能保证原子性?
简单直接的答案是:因为 Redis 的主工作线程是单线程的,且 Lua 脚本在执行时是“排他”的。
我们可以把 Redis 想象成一个只开了一个窗口的办事大厅,而 Lua 脚本就是一份必须一次性办完的复杂文件。
以下是深度的技术原理拆解,帮助你在面试中不仅能答对,还能答出深度:
1. 核心机制:单线程 + 独占模式
Redis 的核心命令执行器是单线程的(Event Loop)。
-
普通命令(如 SET/GET): Redis 会从队列里一个个取出来执行。A 客户端发一个 SET,B 客户端发一个 GET,它们是排队轮流执行的。
-
Lua 脚本(EVAL): 当 Redis 读到
EVAL命令(执行 Lua 脚本)时,它会进入一种独占模式。-
Redis 会暂停处理所有其他客户端发来的请求。
-
它把整个 Lua 脚本作为一个整体交给 Lua 解释器执行。
-
只有当脚本执行结束(或者超时),Redis 才会恢复去处理请求队列里排队的下一个命令。
-
结论: 在 Lua 脚本执行期间,绝对不会有其他客户端的命令插队。这就从物理上保证了脚本内的操作是不可分割的(Indivisible),也就是原子性。
面试高阶陷阱:此“原子性”非彼“原子性”
这是面试官最喜欢挖的坑,一定要主动指出来:
Redis Lua 脚本的“原子性”是指“隔离性 (Isolation)”,而不是数据库事务中的“原子性 (Atomicity,要么全做要么全不做)”。
-
SQL 事务: 如果中间报错,会回滚 (Rollback),像什么都没发生过一样。
-
Redis Lua: 如果脚本里有 3 条命令,执行到第 2 条报错了:
-
第 1 条已经生效的数据不会回滚!
-
第 2 条报错停止。
-
第 3 条不会执行。
-
脚本结束。
-
面试话术:
“Redis 的 Lua 脚本保证的是执行过程不被其他客户端打断,保证了操作的原子隔离性。但是,Redis 不支持回滚 (Rollback)。如果脚本内部逻辑抛出错误,之前执行成功的写操作是无法撤销的。所以在编写 Lua 脚本时,必须保证代码逻辑的健壮性。”
我的简历中使用了 Redisson 的 RRateLimiter ,这个组件的底层就是纯 Lua 脚本实现的。
可以这样举例:
“比如我在项目中使用的令牌桶限流。
我需要查询当前令牌够不够(GET)。
如果够,我就要扣减一个令牌(DECR)。
这两个操作如果分开执行,在高并发下会出现‘超卖’(两个线程同时看到令牌剩余 1 个,结果都扣减了,变成 -1)。 而 Redisson 将这两个动作封装在一个 Lua 脚本里发给 Redis,因为 Lua 的原子性,这两个动作瞬间完成,中间没缝隙,绝对不会出现超卖。”
为什么这比 Redis原生事务更强?
Redis 原生事务(MULTI/EXEC)存在一个痛点:CAS (Check-And-Set) 问题。
-
Redis 事务流程: 你必须先
GET一个值到客户端,判断一下(Check),然后再发SET命令(Set)。 -
竞态条件: 在你
GET之后、SET之前,因为网络延迟,另一个客户端可能修改了这个值。虽然WATCH可以监控变化并取消事务,但这意味着你需要写重试逻辑,高并发下失败率极高。 -
Lua 的优势: 逻辑直接在服务端运行。
GET和SET之间没有网络通信延迟,且中间没有其他命令插入。你可以放心地读取一个值,修改它,再写回去,完全不用担心期间被别人改了。
介绍一下虚拟内存
虚拟内存 (Virtual Memory),一言以蔽之,是操作系统对所有进程撒的一个弥天大谎。
它给每个进程(比如你的 Java 程序)营造了一个美丽的幻觉:
“兄弟,这整个电脑的内存全是你的!是连续的!是独占的!你想怎么用怎么用,不用管别人。”
但实际上,物理内存(RAM)可能早就被碎尸万段,甚至塞满了,部分数据都被赶到硬盘上去了。
在很久以前(DOS 时代),确实没有虚拟内存。程序直接操作物理地址。 这会导致三个严重问题:
-
打架(地址冲突):
-
QQ 说:“我要住 101 号房间。”
-
微信说:“我也要住 101 号房间。”
-
崩了。程序员必须小心翼翼地规划,谁用哪块地。
-
-
偷窥(不安全):
-
QQ 住 101,微信住 102。
-
微信稍微伸个头,就能看到 QQ 在 101 房间里的隐私(读取内存数据)。恶意程序可以随意修改操作系统的核心数据。
-
-
不够用(内存不足):
- 你有 4GB 内存,GTA5 游戏要 8GB。直接报错退出,玩不了。
二、 虚拟内存的机制(怎么圆这个谎?)
为了解决上面的问题,操作系统引入了中间商。
1. 核心道具:页表 (Page Table) & MMU
-
虚拟地址 (Virtual Address):进程手里拿到的房卡号(比如 0x001)。这是假的。
-
物理地址 (Physical Address):内存条上真正的存储单元地址(比如 0x8F3)。这是真的。
-
映射表 (Page Table):记录“假房号”对应“真房号”的小本本。
-
MMU (Memory Management Unit):CPU 里专门负责查表的一个硬件单元。
2. 工作流程
当你的 Java 程序执行指令 int a = 10 (假设要把 10 写到地址 0x001):
-
进程发出指令:“我要往 0x001 写数据!”(这是虚拟地址)。
-
MMU 拦截:“稍等,我查一下表。”
- MMU 查页表发现:进程 A 的 0x001 对应物理内存的 0x8F3。
-
硬件执行:CPU 把数据写到了物理内存的 0x8F3。
妙在哪里?
-
QQ 往 0x001 写数据 -> 映射到物理地址 0x800。
-
微信 往 0x001 写数据 -> 映射到物理地址 0x900。
-
虽然他们用的虚拟地址一样,但物理上完全隔离,互不干扰!
缺页中断 (Page Fault) —— “空手套白狼”
这是虚拟内存最骚的操作。
你的 Java 程序申请了 1GB 内存(比如 new byte[1024*1024*1024])。
操作系统直接答应:“好,给你 1GB!”(虚拟内存里划给你了)。 但实际上,物理内存里 1KB 都没给你分配。
-
当你真正开始写数据时:
-
CPU 拿着虚拟地址去查表。
-
MMU 发现:“夷?这个页在物理内存里不存在(Valid 位是 0)。”
-
触发 缺页中断 (Page Fault)。
-
操作系统内核醒来:“哎呀,这小子来真的了。”
-
操作系统赶紧找一块空闲的物理内存,分配给这个页,更新映射表。
-
让 CPU 重新执行刚才的写入指令。
-
这就是为什么 Java 启动时申请大内存很快,但实际占用(RES)是随着运行慢慢涨上去的。
交换 (Swap) —— 硬盘来凑数
如果物理内存真满了(比如开了几十个 Chrome 标签页),怎么办?
-
动作:操作系统会把那些很久没用的页(冷数据),从物理内存里踢出来,写到硬盘上(Swap 分区 / pagefile.sys)。
-
腾地:物理内存腾出来了,给当前急用的程序用。
-
换回:当你突然切回那个很久没用的 Chrome 标签页,操作系统会再触发缺页中断,把硬盘里的数据读回物理内存(这时候你会感觉电脑卡了一下,硬盘灯狂闪)。
操作系统中有很多内存淘汰策略,比如LRU,LFU,CLOCK,增强CLOCK等
进程切换和线程切换的区别?
1.进程切换:进程切换涉及到更多的内容,包括整个进程的地址空间、全局变量、文件描述符等。因此,进程切换的开销通常比线程切换大。 2.线程切换:线程切换只涉及到线程的堆栈、寄存器和程序计数器等,不涉及进程级别的资源,因此线程切换的开销较小。
线程切换为什么比进程切换快,节省了什么资源?
线程切换比进程切换快是因为线程共享同一进程的地址空间和资源,线程切换时只需切换堆栈和程序计数器等少量信息,而不需要切换地址空间,避免了进程切换时需要切换内存映射表等大量资源的开销,从而节省了时间和系统资源。
JNI 是什么?
它在 Java 编程中是一个非常重要的机制,主要用于解决 Java 应用程序需要与本地代码(Native Code)交互的问题。
JNI 的核心概念与作用
1. 核心定义
JNI 是一套编程接口,它允许运行在 Java 虚拟机(JVM) 上的 Java 代码与用其他语言(如 C、C++ 等)编写的本地应用程序和库进行交互。
2. 主要作用
-
调用本地库 (Calling Native Libraries): 允许 Java 程序调用操作系统底层功能、硬件设备驱动程序,或者使用已经存在的、用 C/C++ 等语言编写的高性能库。
-
提高性能 (Performance Enhancement): 对于对性能要求极高或需要直接操作硬件的代码块,可以将其用 C/C++ 实现,并通过 JNI 在 Java 中调用,以提升执行效率。
-
复用现有代码 (Reusing Existing Code): 允许开发者在 Java 项目中重用大量的现有 C/C++ 代码库,而无需将其完全重写成 Java。
JNI 的缺点
虽然 JNI 很强大,但它也有一些缺点:
-
失去跨平台性: 一旦使用 JNI,你的 Java 程序就依赖于特定的本地库文件,从而失去了 Java “一次编译,到处运行” 的跨平台优势。
-
开发复杂性: JNI 的开发过程比纯 Java 复杂,需要处理 C/C++ 代码、头文件生成、本地内存管理和垃圾回收的交互等问题。
-
安全和稳定性风险: 本地代码不受 JVM 内存管理和安全机制的保护。如果本地代码有内存泄漏或越界访问等错误,可能导致整个 JVM 崩溃。
SpringBoot程序的JDBC连接到了MySQL,用的是UDS,请问流程是什么
场景准备
-
主角 A (Spring Boot):位于 Linux 系统的一个进程(假设 PID=100)。
-
主角 B (MySQL):位于 Linux 系统的另一个进程(假设 PID=200)。
-
秘密通道 (UDS 文件):MySQL 在启动时,会在硬盘上创建一个特殊文件,通常位于
/var/lib/mysql/mysql.sock(这个路径在my.cnf里配置)。
配置上的不同(这是关键第一步): 平时你连数据库,URL 写的是 jdbc:mysql://127.0.0.1:3306/...。
用 UDS 时,你的 JDBC URL 会变得很奇怪,大概长这样(取决于具体的驱动实现,通常需要引入 junixsocket 等库配合):
Properties
|
|
二、 详细连接流程(从发起请求到拿到数据)
假设你的 Controller 收到一个请求,要查 SELECT * FROM users。
第一阶段:建立连接(握手)
-
Java 发起系统调用:
-
Spring Boot (JDBC 驱动) 解析 URL,发现要用 UDS。
-
它不再调用 TCP 的
connect(ip, port),而是调用针对文件的系统调用socket(AF_UNIX, ...)和connect("/var/lib/mysql/mysql.sock")。
-
-
操作系统(内核)介入:
-
内核看到 Java 想连
/var/lib/mysql/mysql.sock。 -
权限检查:内核检查运行 Java 进程的用户(比如
app_user)有没有对这个 sock 文件的读写权限。如果没有,直接报错Permission denied。 -
查找绑定:内核查看记录表,发现这个 sock 文件正被 PID=200 (MySQL) 监听(Listen)着。
-
-
建立通道:
-
内核在内存里,直接在 PID=100 (Java) 和 PID=200 (MySQL) 之间搭了一根“虚拟管子”。
-
分配句柄:
-
给 Java 进程发一个文件句柄(FD),比如 FD=8。
-
给 MySQL 进程发一个文件句柄(FD),比如 FD=12。
-
-
此时,连接建立完成。不需要 TCP 的三次握手(SYN, SYN-ACK, ACK),只有文件系统的查找开销。
-
第二阶段:发送 SQL(写数据)
-
Java 写数据:
-
Spring Boot 把 SQL 语句
SELECT * FROM users转成字节流。 -
调用系统调用
write(FD=8, "SELECT...")。
-
-
内核搬运(最快的部分):
-
没有协议栈:内核不需要给数据包加 TCP 头、IP 头、不需要算校验和,也不需要路由查找。
-
直接拷贝:内核直接把 Java 进程 发送缓冲区 里的数据,拷贝到 MySQL 进程的 接收缓冲区 里。
-
MySQL 那个监听的 FD=12 变得“可读”。
-
-
MySQL 读数据:
- MySQL 被唤醒,调用
read(FD=12),拿到了 SQL 语句。
- MySQL 被唤醒,调用
第三阶段:返回结果(读数据)
-
MySQL 处理:
- MySQL 解析 SQL,查自己的 B+ 树,找到了 10 条用户数据。
-
MySQL 写回:
- MySQL 调用
write(FD=12, [用户数据])。
- MySQL 调用
-
内核再次搬运:
- 内核把数据直接从 MySQL 的内存搬运到 Java 的内存缓冲区。
-
Java 拿到结果:
- Spring Boot 从
read(FD=8)中苏醒,拿到 ResultSet,封装成对象返回给 Controller。
- Spring Boot 从
如果用 TCP (127.0.0.1) 流程有啥区别?
为了让你更直观地看到 UDS 省了啥,我们看看普通的 Localhost TCP 连接多了哪些步骤:
-
打包:Java 把 SQL 加上 TCP 头(源端口、目标端口)、IP 头(源IP 127.0.0.1、目标IP 127.0.0.1)。
-
计算:CPU 计算 TCP 校验和。
-
路由:内核网络层查路由表,发现是回环地址(Loopback)。
-
伪装发送:数据包虽然不出网卡,但要在内核的协议栈里走一圈“虚拟出网再入网”的流程(MTU检查、防火墙规则检查 iptables 等)。
-
拆包:MySQL 端收到后,去掉 IP 头、去掉 TCP 头,校验数据的完整性。
总结差异:
-
TCP 方式:就像你写了一封信,虽然寄给同一个办公室的同事,但你还是把它扔进了楼下的邮局信箱。邮局(内核网络栈)盖戳、分拣、再投递回同一个办公室。
-
UDS 方式:你直接站起来,把信放在了同事的桌子上。
Redis把数据从内核内存区拷贝到用户内存的过程
详细流程图解(从 Socket 到 Redis)
假设一个客户端发来了 GET user:1。
第一步:数据到达内核
-
网卡接收到光信号/电信号,转成数据包。
-
DMA (直接内存访问) 把数据包拷贝到内核的内存(Socket 接收缓冲区)。
-
内核检查这根 Socket 对应的句柄(FD),发现 Redis 之前通过
epoll_ctl关注了它的“可读事件”。 -
内核动作:把这个 FD 加入到 就绪链表 (Ready List) 中。
第二步:Redis 醒来
-
Redis 主线程一直在跑一个死循环(
aeMain)。 -
循环里调用了
epoll_wait。 -
刚才数据一到,
epoll_wait立刻返回,告诉 Redis:“嘿,FD=5 是可读的!”
第三步:读取与执行
-
Redis 根据 FD=5,找到对应的处理函数(通常是
readQueryFromClient)。 -
系统调用
read:把数据从内核搬运到 Redis 的用户态 Buffer。 -
协议解析:解析 RESP 协议,知道你要执行
GET。 -
查字典:在内存的 HashMap 里找到
user:1的值。 -
准备回复:把结果写入到客户端对象的发送缓冲区。
第四步:回复客户端
-
如果发送缓冲区很小,Redis 直接当场就调用
write发回去了。 -
如果发送缓冲区满了(或者内核的写缓冲区满了),Redis 会向 epoll 注册一个 “写事件”。
-
等下次内核告诉 Redis “这个 Socket 可以写了”,Redis 再继续把剩下的数据发完。
操作系统的IO多路复用select,poll,epoll
poll和 select 并没有太大的本质区别,都是使用「线性结构」存储进程关注的 Socket 集合,因此都需要遍历文件描述符集合来找到可读或可写的 Socket,时间复杂度为 O(n),而且也需要在用户态与内核态之间拷贝文件描述符集合,这种方式随着并发数上来,性能的损耗会呈指数级增长。
-
epoll 在内核里使用红黑树来跟踪进程所有待检测的文件描述字,把需要监控的 socket 通过epoll_ctl0 函数加入内核中的红黑树里,红黑树是个高效的数据结构,增删改一般时间复杂度是O(logn)。而 select/poll 内核里没有类似 epol 红黑树这种保存所有待检测的 socket 的数据结构,所以select/pol 每次操作时都传入整个 socket 集合给内核,而 epoll 因为在内核维护了红黑树,可以保存所有待检测的 socket ,所以只需要传入一个待检测的 socket,减少了内核和用户空间大量的数据拷贝和内存分配。
-
epoll 使用事件驱动的机制,内核里维护了一个链表来记录就绪事件,当某个 socket 有事件发生时,通过回调函数内核会将其加入到这个就绪事件列表中,当用户调用 epoll_wait0 函数时,只会返回有事件发生的文件描述符的个数,不需要像 select/poll 那样轮询扫描整个 socket 集合,大大提高了检测的效率。
我们来看一个最经典的场景:Redis 怎么把数据发给客户端? 假设 Redis 要发送字符串 "Hello"。
1. 物理位置
-
字符串 “Hello”:一开始在 Redis 的用户内存里。
-
Socket 对象:在操作系统的内核内存里。
2. 发送过程 (write)
Redis 调用 write(fd, "Hello") 系统调用。
-
步骤 A:跨界拷贝(CPU Copy) CPU 暂停 Redis 的用户态运行,切换到内核态。 CPU 把 “Hello” 从 Redis 的用户内存 复制到 Socket 的发送缓冲区(内核内存)。 注意:这时候数据其实还在内存里,没出去呢!
-
步骤 B:DMA 拷贝 操作系统看“发送缓冲区”里有货了,就命令 网卡(硬件): “喂,把这块内存里的数据拿走发出去。” 网卡的 DMA 控制器直接把数据从内核内存搬运到网卡硬件上,然后变成电信号发走。
3. 接收过程 (read)
客户端发来了一条命令 "GET"。
-
步骤 A:硬件接收 网卡收到电信号,转成数据包,通过 DMA 搬运到 Socket 的接收缓冲区(内核内存)。 此时,Redis 还不知道数据来了。
-
步骤 B:通知与唤醒 (Epoll) 内核发现这个 Socket 的接收缓冲区有数据了,于是通过 Epoll 告诉 Redis:“FD=5 有读事件了!”
-
步骤 C:跨界拷贝(CPU Copy) Redis 醒来,调用
read(fd)。 CPU 把数据从 Socket 的接收缓冲区(内核内存) 复制到 Redis 的用户内存。 现在,Redis 终于可以在自己的变量里看到"GET"这三个字母了。
内核内存和Socket是什么?
内核内存 (Kernel Memory) —— “皇宫禁地”
在 Linux 操作系统中,物理内存(RAM)被逻辑上划分为两块:
-
用户空间 (User Space):
-
谁在住? 你的 Java 程序、Chrome 浏览器、QQ 等所有应用程序。
-
地位:平民百姓。权力有限,想干大事(读硬盘、发网络包)必须打报告(系统调用)。
-
特点:如果你的 Java 程序崩了,只是这块地盘乱了,不会影响整个电脑。
-
-
内核空间 (Kernel Space) / 内核内存:
-
谁在住? 操作系统内核(Linux Kernel)、硬件驱动程序。
-
地位:皇宫禁地(VIP)。拥有最高权限,可以随意操作 CPU、硬盘、网卡。
-
特点:Socket 就存放在这里! 还有页表、进程表等核心数据。如果这里崩了,电脑直接蓝屏或重启。
-
为什么要有“内核内存”? 主要是为了安全和隔离。防止你写了一个只有 bug 的代码,直接把操作系统的核心数据给改了,导致系统瘫痪。
Socket 是什么?—— “插座与缓冲区”
“Socket” 翻译过来叫“插座”或“套接字”。 但这个翻译太抽象了。在内核内存的视角里,Socket 到底是什么?
本质上,Socket 就是内核内存里的两个缓冲区(Buffer)结构体。
当你用 Java new Socket() 创建一个连接时,内核会在内核内存里划出一小块地盘,专门维护这个连接。这块地盘里主要包含两部分:
-
接收缓冲区 (Recv Buffer):
-
像一个收件箱。
-
网卡收到网线传来的数据,会先扔进这个箱子,等着你的 Java 程序来取。
-
-
发送缓冲区 (Send Buffer):
-
像一个发件箱。
-
你的 Java 程序想发数据,先把数据扔进这个箱子,然后由操作系统择机发给网卡。
-
传统的Java17,是用户级线程和内核级线程一对一处理
在 Java 19(虚拟线程/协程)普及之前,Java 17 及更早版本,采用的确实是经典的 1:1 线程模型。
这意味着:每一个 Java 线程(User Thread),在底层都死死绑定着一个操作系统的内核线程(Kernel Thread)。
一、 核心关系:傀儡与真身
在 1:1 模型中,Java 线程和内核线程的关系,就像是 “皮影戏的傀儡” 和 “幕后的操纵者”。
-
Java 线程 (User Thread):
-
这是你在代码里
new Thread()创建出来的对象。 -
它只是一个傀儡(皮影)。它有名字、有属性(ID、Priority),但它自己是没有生命的,动不起来。
-
它生活在 JVM 的堆内存 里(用户态)。
-
-
内核线程 (Kernel Thread / KLT):
-
这是操作系统(Linux/Windows)真正创建出来的工人。
-
它是幕后的操纵者。只有它才能被 CPU 调度,只有它才有资格进 CPU 干活。
-
它生活在 内核空间 里。
-
所谓 1:1 映射:就是当你调用 thread.start() 时,JVM 会通过系统调用(System Call),向操作系统申请一个内核线程,然后把这个 Java 线程对象和那个内核线程**“绑死”**在一起。此后,这个 Java 线程的一举一动,其实都是那个内核线程在干活。
二、 它们怎么“通信”?(控制权传递)
你问的“通信”,其实不是像发微信那样发消息,而是指令下达和状态同步。这一切都是通过 JNI (Java Native Interface) 和 系统调用 (System Call) 完成的。
我们可以把这想象成牵线的过程。
1. 启动指令:start()
-
Java 层:你喊了一句
t1.start()。 -
通信过程:
-
Java 方法调用
private native void start0()。 -
这就触碰到了 JVM 的 C++ 代码。
-
JVM 向操作系统发起系统调用:
clone()(Linux) 或CreateThread(Windows)。 -
操作系统:收到请求,创建一个真正的内核线程。
-
绑定:JVM 把这个内核线程的 ID 记在 Java 线程对象里(建立了 1:1 关系)。
-
2. 行为控制:sleep() / yield() / park()
-
场景:你在 Java 代码里写了
Thread.sleep(1000)。 -
通信过程:
-
Java 线程(傀儡)说:“我要睡一秒。”
-
JVM 识别到这是个 Native 方法。
-
JVM 发起系统调用,告诉内核:“喂,把你手里控制这个 Java 线程的那个内核线程挂起(Suspend)1秒。”
-
操作系统:把对应的内核线程从 CPU 上也就是“运行队列”里拿下来,扔到“等待队列”里。
-
结果:Java 线程看起来停了,其实是背后的内核线程停了。
-
3. 阻塞同步:IO 操作
-
场景:你读取文件
fis.read()。 -
通信过程:
-
Java 代码执行到读取指令。
-
因为读取硬盘是特权操作,Java 线程自己干不了,必须陷入内核态。
-
对应的内核线程发起 IO 请求,然后被操作系统阻塞(因为它要等硬盘转圈圈)。
-
反馈:内核线程不动了,Java 线程的状态也就变成了
BLOCKED或RUNNABLE(但在等待 syscall 返回)。
-
三、 它们怎么调度?(谁说了算?)
这是最关键的:JVM 完全不管调度!JVM 是没有资格分配 CPU 时间片的。
在 1:1 模型下,Java 线程的调度完全交给操作系统的调度器(Scheduler)。
1. 调度者:OS 调度器(比如 Linux 的 CFS)
JVM 就像一个劳务派遣公司,它把人(线程)招进来,交给政府(OS)去管理。至于谁先干活、谁后干活、干多久,全看政府的心情。
2. 调度方式:抢占式 (Preemptive)
操作系统是个独裁者,它采用**“抢占式”**调度。
-
时间片(Time Slice):
-
OS 给每个内核线程分配一小段 CPU 时间(比如 10ms - 100ms)。
-
时间一到,CPU 内部的时钟中断响铃。
-
OS 强行把当前线程踢下来(哪怕你代码还没跑完),换下一个线程上。
-
-
上下文切换 (Context Switch) —— 昂贵的代价: 这就是 1:1 模型最大的痛点。当 OS 决定切换线程时:
-
保存现场:把当前内核线程的寄存器值、程序计数器(跑到哪一行了)全部存回内存。
-
刷新缓存:因为换人了,CPU L1/L2 缓存里的数据大部分都废了,需要重新加载。
-
恢复现场:把下一个要运行的内核线程的信息读进寄存器。
-
3. Java 优先级的尴尬
Java 里有 Thread.setPriority(1-10)。
-
现实:这玩意儿基本是个心理安慰。
-
原因:Java 的优先级只是给 OS 一个“建议”。由于不同操作系统对优先级的定义不同(Linux 甚至可能忽略它),JVM 传过去之后,OS 可能会说:“好的我知道了,但我还是按我的规则办。”
synchronized的底层原理
第一层:数据结构层 —— Mark Word 的比特位舞步
在 64 位 JVM 中,对象头(Object Header)里的 Mark Word 是 8 个字节(64 bit)。synchronized 的所有状态流转,本质上就是在修改这 64 个 bit。
我们需要关注最后 2 位(锁标志位)和倒数第 3 位(偏向锁位):
| 锁状态 | 25 bit (未使用) | 31 bit (HashCode) | 1 bit (未用) | 4 bit (分代年龄) | 1 bit (偏向锁位) | 2 bit (锁标志位) |
|---|---|---|---|---|---|---|
| 无锁 | … | HashCode | 0 | age | 0 | 01 |
| 偏向锁 | ThreadID (54bit) | Epoch (2bit) | … | age | 1 | 01 |
| 轻量级锁 | 指向栈中 Lock Record 的指针 (62bit) | … | … | … | … | 00 |
| 重量级锁 | 指向互斥量(Monitor)的指针 (62bit) | … | … | … | … | 10 |
| GC 标记 | … | … | … | … | … | 11 |
-
底层细节:
-
当锁是 轻量级锁 (00) 时,前 62 位不再存 HashCode,而是存一个内存地址指针,指向持有锁线程的栈帧。
-
当锁是 重量级锁 (10) 时,前 62 位指向堆内存中 C++ 定义的
ObjectMonitor对象。
-
第二层:栈帧层 —— Lock Record (锁记录)
在轻量级锁阶段,JVM 并不想直接请求操作系统,它玩了一个“偷梁换柱”的把戏。
-
开辟空间:当代码进入
synchronized块,如果当前是无锁状态,JVM 会在当前线程的栈帧中创建一个名为Lock Record的空间。 -
Displaced Mark Word:JVM 把对象头里原本的 Mark Word 拷贝一份到这个
Lock Record中(为了保存原本的 HashCode 和分代年龄,等锁释放了还得还回去)。 -
CAS 争抢:JVM 尝试用 CAS (Compare And Swap) 指令,将对象头里的 Mark Word 替换为指向
Lock Record的指针。-
成功:对象头变成了“指针 + 00”,代表抢锁成功。
-
失败:说明有竞争,或者已经锁了。JVM 会检查对象头的指针是不是指向我自己的栈?如果是,说明是重入锁,只需在栈里再放一个空的 Lock Record 记录重入次数即可。
-
第三层:JVM 实现层 —— C++ 里的 ObjectMonitor
当竞争升级为重量级锁,JVM 会去堆中申请一个 C++ 对象:ObjectMonitor。
在 OpenJDK 的 HotSpot 源码中 (src/share/vm/runtime/objectMonitor.hpp),它的核心结构如下:
|
|
底层竞争流程(硬核版):
-
CAS 抢占:线程尝试通过 CAS 将
_owner指针指向自己。成功则执行。 -
自旋失败,入队:如果抢不到,线程被封装成
ObjectWaiter对象。 -
进入 cxq:线程首先通过 CAS 尝试把节点插入
_cxq队列的头部(LIFO 策略,为了减少尾部维护开销)。 -
OnDeck 机制:JVM 不会把所有人都唤醒,而是通过策略挑选一个继承人(Heir),称为
OnDeck,只有这个线程会去竞争锁,避免“惊群效应”。
第四层:操作系统与硬件层 —— Futex 与 内存屏障
这是最底下的地基,也是为什么重量级锁慢的原因。
1. 操作系统:Mutex 与 Futex
当线程在 ObjectMonitor 里抢不到锁,需要“阻塞(Block)”时,JVM 会调用操作系统的内核函数。
-
Linux 环境下:
-
早期:直接用
pthread_mutex_lock,这需要从用户态(User Mode)切换到内核态(Kernel Mode)。这个切换涉及到保存 CPU 寄存器上下文、刷新 CPU 缓存(L1/L2 Cache 失效)等,开销极大。 -
现代优化 (Futex):Linux 提供了
futex(Fast Userspace muTEX)。-
它先在用户态尝试通过 CAS 修改一个整数。
-
只有当 CAS 失败(确实有竞争),才会调用系统调用(System Call)陷入内核态去执行
sem_wait让线程挂起。
-
-
park():Java 中的
LockSupport.park()底层就是调用了futex相关的系统调用。
-
2. CPU 硬件:内存语义 (JMM)
synchronized 不仅仅是锁,它还保证了 内存可见性。
-
Lock (monitorenter):
-
底层会插入一个 LoadBarrier(或类似的刷新指令)。
-
强制让当前线程的工作内存(CPU Cache)失效,必须从主内存重新读取变量。
-
-
Unlock (monitorexit):
-
底层会插入一个 StoreBarrier(写屏障)。
-
强制将工作内存中的最新修改立即刷新回主内存,确保别的线程能看到。
-
-
确保每次都能读到业务的最新的缓存信息,比如剩余票数还剩1个,把之前获取锁之前获取到的2给删了,重新更新为最新值,然后在把剩余票数变为0个。
总结:一条线程的“黑化”之路
如果一个 Java 线程去抢 synchronized:
-
CPU 指令层:先尝试 CAS 修改对象头。
-
栈帧层:如果失败,检查是否是自己锁的(重入),或者尝试把 Mark Word 复制到自己栈帧(轻量级锁)。
-
C++ 对象层:还失败?去堆里找
ObjectMonitor,把自己包装成ObjectWaiter节点,拼命往_cxq队列头挤。 -
OS 内核层:挤不进去?调用
futex系统调用,请求操作系统把自己挂起(Sleep),交出 CPU 时间片,从用户态跌落内核态,等待被唤醒。
介绍一下Java里的volatile
volatile 是 Java 虚拟机(JVM)提供的一种轻量级的同步机制。在并发编程中,它通常被用来修饰变量。
理解 volatile,核心要抓住这三大特性:可见性、有序性,以及它不保证原子性。
以下是详细的拆解:
1. 核心特性
A. 保证可见性 (Visibility)
这是 volatile 最主要的作用。
-
问题背景: 在 Java 内存模型 (JMM) 中,每个线程都有自己的工作内存 (Working Memory,对应 CPU 缓存),变量存储在主内存 (Main Memory) 中。线程操作变量时,会先将变量从主内存拷贝到自己的工作内存中。如果线程 A 修改了变量,线程 B 可能还在读取自己缓存中的旧值,导致数据不一致。
-
volatile 的作用:
-
当一个线程修改了
volatile变量的值,新值会立即刷新到主内存。 -
同时,会强制让其他线程工作内存中该变量的缓存失效。
-
当其他线程需要读取该变量时,必须重新从主内存读取最新值。
-
B. 禁止指令重排序 (Ordering)
-
问题背景: 为了提高性能,编译器和处理器通常会对指令进行重排序(即代码执行顺序可能与编写顺序不同),只要不影响单线程下的结果即可。但在多线程环境下,重排序可能导致严重的逻辑错误(例如:对象初始化了一半就被另一个线程使用了)。
-
volatile 的作用: JVM 会通过插入内存屏障 (Memory Barrier) 来禁止特定类型的指令重排序,从而保证有序性。
- 经典案例: 单例模式的“双重检查锁”(Double-Checked Locking)。如果不加
volatile,可能导致拿到一个未完全初始化的对象。
- 经典案例: 单例模式的“双重检查锁”(Double-Checked Locking)。如果不加
C. 不保证原子性 (No Atomicity)
这是面试和开发中最大的坑。
-
现象:
volatile不能替代synchronized或Lock。 -
例子: 对一个
volatile int count执行count++操作。-
count++包含三个步骤:读值 -> 加 1 -> 写回。 -
如果两个线程同时读到了 100,都加 1,然后都写回 101。最终结果是 101,而不是期望的 102。
-
-
结论: 对于复合操作(Read-Modify-Write),
volatile无法保证线程安全。
3. 什么时候使用 volatile?
由于 volatile 比 synchronized 开销小(因为它不会引起线程上下文切换),在满足以下两个条件时,推荐使用:
-
对变量的写操作不依赖于当前值(例如:不是
i++,而是flag = true)。 -
该变量没有包含在具有其他变量的不变式中。
常见场景 1:状态标记量 (Flag)
用于控制线程停止或状态切换。
|
|
常见场景 2:单例模式 (Double-Checked Locking)
这是 volatile 防重排最经典的应用。
|
|
4. 总结:volatile vs synchronized
| 特性 | volatile | synchronized |
|---|---|---|
| 可见性 | 保证 | 保证 |
| 有序性 | 保证 | 保证 |
| 原子性 | 不保证 | 保证 |
| 线程阻塞 | 不会阻塞线程 | 会阻塞线程 |
| 适用范围 | 仅变量 | 方法、代码块 |
| 性能 | 较高 (轻量级) | 较低 (重量级,尽管已有优化) |
一句话总结: volatile 是 Java 提供的轻量级同步机制,它主要用于保证多线程下的变量可见性和禁止指令重排,但它不能保证原子性,因此不能完全替代锁。
它保证的“顺序”:禁止内部瞎优化(指令重排)
CPU 和编译器为了快,有时候会把你写的代码顺序打乱(只要单线程下逻辑通顺就行)。
-
Volatile 的作用: 告诉 CPU,“这行代码很关键,别给我乱动位置”。
-
例子:
-
你写的是:
步骤1 -> 步骤2 -> volatile写 -
CPU 不允许优化成:
volatile写 -> 步骤1 -> 步骤2 -
这就是你说的“保证代码执行顺序不改变”。
-
2. 它无法改变的“并发”:无法阻止外部线程的“插队”
这正是你后半句说的重点。volatile 不是锁。
-
没有排他性: 它不能像
synchronized那样让线程排队(Serial Execution)。 -
现象: 线程 A 和线程 B 可以同时去修改这个
volatile变量。 -
后果: 如果操作不是原子的(比如
i++),大家还是会“撞车”。
讲解Java的ThreadLocal
ThreadLocal 是 Java 中一个非常重要且高频面试的并发工具类。它的核心思想是 “空间换时间”,为每个线程提供独立的变量副本,从而实现线程隔离。
以下我将从核心概念、应用场景、底层原理(源码级别)、内存泄漏问题以及最佳实践五个维度为你详细讲解。
1. 核心概念
ThreadLocal(线程局部变量)提供了线程本地变量。当你在代码中创建一个 ThreadLocal 变量时,访问这个变量的每个线程都会拥有一个独立的、自己的本地副本。
-
它的作用: 它是为了解决多线程并发访问共享变量时的线程安全问题,但它不是通过加锁(
synchronized)来实现的,而是通过让每个线程自己玩自己的,互不干扰。 -
比喻:
-
synchronized就像只有一个厕所,大家需要排队(锁),同一时间只能一个人用。 -
ThreadLocal就像给每个人发了一个专用的移动厕所,大家互不影响,不需要排队。
-
2. 核心应用场景
ThreadLocal 主要有两个经典的使用场景:
-
线程隔离(每个线程需要一个独享的对象):
-
典型案例:
SimpleDateFormat。它是线程不安全的,如果把它定义为static并在多线程中共用,会报错。 -
解法: 使用
ThreadLocal为每个线程创建一个单独的SimpleDateFormat副本。 -
案例: 数据库连接(Connection)、Session 管理。
-
-
上下文传递(跨方法传递参数):
-
场景: 在一个 Web 请求中,从 Controller -> Service -> DAO,我们需要传递用户信息(User ID)。
-
问题: 如果每个方法都加一个
userId参数,代码会非常臃肿。 -
解法: 在拦截器处将 User ID 存入
ThreadLocal,后续任何地方都可以直接取出来使用,无需层层传参。
-
3. 底层原理(重点:ThreadLocalMap)
这是理解 ThreadLocal 的关键。很多人误以为 ThreadLocal 内部维护了一个 Map,Key 是线程,Value 是值。其实恰恰相反。
3.1 真实的存储结构
-
Thread 类中: 每个
Thread对象内部维护了一个成员变量threadLocals。Java
1 2// Thread.java 源码片段 ThreadLocal.ThreadLocalMap threadLocals = null; -
ThreadLocalMap: 这是一个类似于
HashMap的结构,但它是ThreadLocal的静态内部类。 -
Key 和 Value:
-
Key: 是当前的
ThreadLocal对象实例本身(而且是弱引用,WeakReference)。 -
Value: 是我们
set进去的具体值。
-
3.2 引用关系图
|
|
结论: 数据其实是存放在线程对象(Thread)自己的堆内存里的,ThreadLocal 仅仅是一个访问入口(Key)。
3.3 Hash 冲突解决
与 HashMap 使用链表法/红黑树不同,ThreadLocalMap 使用的是 线性探测法 (Linear Probing)。
-
如果计算出的槽位(slot)已经被占用了,它就往后找下一个空位存放。
-
这也意味着
ThreadLocal不适合存储极其大量的数据,否则检索效率会下降。
4. 著名的内存泄漏问题
这是 ThreadLocal 最致命的坑,也是面试必问点。
4.1 为什么会泄漏?
ThreadLocalMap 的 Entry 对 Key(ThreadLocal) 是弱引用,但对 Value 是强引用。
-
Key 被回收: 如果外界没有
ThreadLocal的强引用了,在下一次 GC 时,Key 会被回收,Entry 中的 Key 变成了null。 -
Value 还在: 但是,Value 是强引用,只要 Current Thread 还在运行(比如线程池中的核心线程,生命周期很长),这个 Value 就会一直存在于内存中,无法被回收。
-
结果: 出现了一条
Current Thread -> ThreadLocalMap -> Entry -> Value的强引用链,导致 Value 占用的内存无法释放,形成内存泄漏。
4.2 各种补救措施(探测式清理)
Java 的设计者也想到了这点。ThreadLocalMap 在调用 set()、get()、remove() 方法时,会顺便检查 Key 为 null 的 Entry,并将对应的 Value 清除。
4.3 终极解决方案
必须在使用完后,手动调用 remove() 方法。
5. 最佳实践代码示例
无论是在 Spring 的拦截器中,还是日常开发,请务必遵循 try-finally 模式:
|
|
6. 父子线程传递 (InheritableThreadLocal)
普通的 ThreadLocal 无法在子线程中获取父线程设置的值。如果需要传递,可以使用 InheritableThreadLocal。
-
原理: 在创建子线程(Thread 构造函数)时,会自动把父线程的
inheritableThreadLocalsMap 中的数据复制一份给子线程。 -
注意: 仅限创建时复制,后续父线程修改,子线程不可见(拷贝的是引用)。
总结
-
用途: 线程隔离(每个线程一份)和 上下文传递(透传参数)。
-
原理: 每个
Thread内部维护一个ThreadLocalMap,Key 是ThreadLocal实例本身。 -
坑:
-
内存泄漏: 弱引用 Key 导致 Value 滞留。
-
数据污染: 线程池复用线程时,如果没清理,下一个任务会读到上一个任务的数据。
-
-
铁律: 用完必须
remove()。
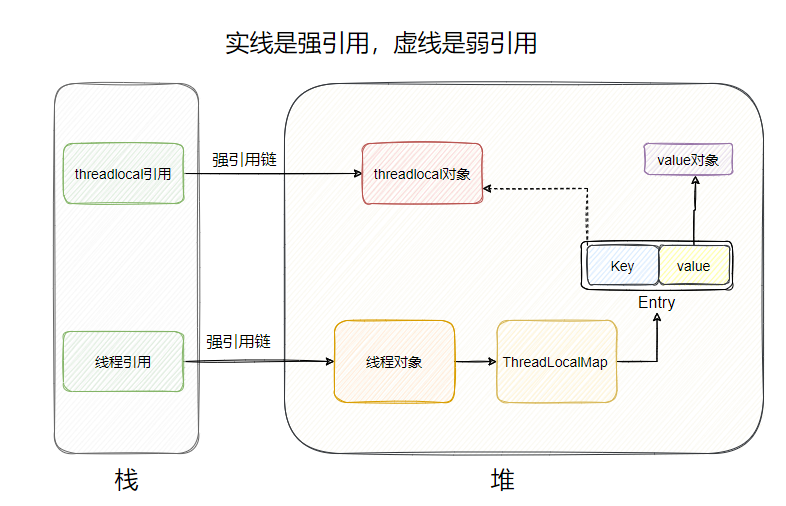
如果不主动区remove(),那么这个threadLocal内部的key-value就会在下一次调用这个线程的时候访问到,产生内存泄漏。
Redo Log是什么
Redo Log(重做日志)是 MySQL 中 InnoDB 存储引擎特有的一种物理日志。
简单来说,它的核心作用是确保事务的持久性(Durability),即防止数据库在发生故障(如断电、宕机)时丢失数据。它是实现 ACID 中 “D” 的关键。
为了帮助你透彻理解(特别是应对面试),我们可以从以下几个维度来解析:
1. 为什么需要 Redo Log?
在 MySQL 中,数据是存在磁盘上的,但为了性能,更新操作通常是在内存(Buffer Pool)中完成的。
-
问题: 如果每次更新数据都直接写回磁盘的数据页(Page),因为数据页在磁盘上是随机分布的,这会产生大量的随机 I/O,性能非常差。
-
解决: 既然直接写数据页太慢,InnoDB 采用了一种策略:当有记录需要更新时,先更新内存,然后把“在某个数据页上做了什么修改”记录到 Redo Log 中。
-
优势: 写 Redo Log 是顺序 I/O(追加写入),速度非常快。
这种技术被称为 WAL (Write-Ahead Logging),即“先写日志,再写磁盘”。
核心场景: 如果 MySQL 突然宕机,内存中的脏页(修改过但还没写回磁盘的数据)会丢失。重启时,MySQL 可以利用磁盘上的 Redo Log 把这些丢失的修改“重做”一遍,从而恢复数据。
2. Redo Log 的工作原理
物理结构
Redo Log 记录的是物理修改。例如:“在第 10 号表空间的第 50 号页面的偏移量 200 处,将值由 A 改为 B”。
写入流程 (循环写入)
Redo Log 的文件大小是固定的(例如配置了 4 个文件,每个 1GB)。InnoDB 使用循环写入(Circular Buffer)的方式来使用这些文件。
想象一个圆形的缓冲区:
-
write pos(当前写入点): 随着事务的执行,不断向前移动,写入新的日志。 -
checkpoint(擦除点/安全点): 也是向前移动。当数据页被真正刷入磁盘后,对应的 Redo Log 就不需要了,可以被覆盖(擦除)。
- 如果
write pos追上了checkpoint: 说明 Redo Log 满了。此时 MySQL 必须暂停更新操作,强制把内存中的脏页刷到磁盘中,以推进checkpoint,腾出空间。
3. 关键参数:innodb_flush_log_at_trx_commit
这是面试中常考的配置项,决定了 Redo Log 何时从内存缓冲区(Redo Log Buffer)刷入磁盘文件。
| 值 | 行为描述 | 安全性 | 性能 |
|---|---|---|---|
| 0 | 每秒将日志写入磁盘一次。事务提交时不强制刷盘。 | 低(崩溃可能丢失1秒数据) | 最高 |
| 1 | (默认) 每次事务提交时,都将日志强制写入磁盘。 | 高(最安全,保证 ACID) | 一般 |
| 2 | 每次事务提交时写到操作系统缓存(OS Cache),由 OS 每秒刷盘一次。 | 中(MySQL挂了没事,OS挂了会丢数据) | 高 |
4. 重点区分:Redo Log vs Binlog
这是面试中最容易混淆的点,必须清晰区分:
| 特性 | Redo Log (重做日志) | Binlog (归档日志) |
|---|---|---|
| 所属层级 | InnoDB 存储引擎层 (特有) | MySQL Server 层 (所有引擎通用) |
| 记录内容 | 物理日志 (在某页做了某修改) | 逻辑日志 (SQL 语句或行数据的变更) |
| 写入方式 | 循环写 (空间固定,会覆盖) | 追加写 (写满一个文件切换下一个,不覆盖) |
| 核心作用 | 崩溃恢复 (Crash-Safe) | 主从复制、数据备份/恢复 |
5. 总结
如果把 MySQL 比如一本账本:
-
数据文件 (ibd) 是厚重的总账本,整理起来很慢。
-
Redo Log 是手边的粉板(或记事贴)。
Bin Log是什么
Binlog(Binary Log,二进制日志)是 MySQL Server 层(即通用层,不依赖于存储引擎)维护的一种日志文件。
如果说 Redo Log 是 InnoDB 引擎的“救命稻草”(用于崩溃恢复),那么 Binlog 就是 MySQL 的**“历史档案”**。
以下是关于 Binlog 的核心知识点,覆盖了原理、用途和常见的面试考点:
1. 核心作用
Binlog 记录了数据库中所有修改数据的操作(如 INSERT, UPDATE, DELETE, CREATE, DROP 等),不包括查询(SELECT, SHOW)。
它的主要用途有两个:
-
主从复制 (Master-Slave Replication):
- 这是最常见的用途。Master 节点把它的 Binlog 传递给 Slave 节点,Slave 接收并重放这些日志,从而保证主从数据一致。
-
数据恢复 (Point-in-Time Recovery):
- 如果数据库误删了数据,可以使用最近的一次全量备份(Full Backup)恢复到某个时间点,然后通过重放 Binlog,把数据恢复到误操作的前一秒。
2. 记录格式 (binlog_format)
这是面试中的高频考点。Binlog 有三种记录模式,各有优劣:
| 格式 | 描述 | 优点 | 缺点 |
|---|---|---|---|
| STATEMENT | 记录执行的 SQL 语句原文(如 UPDATE t SET a=1 WHERE id=10)。 |
日志文件小,网络传输快,IO 压力小。 | 存在数据不一致风险。如果 SQL 中包含 NOW()、UUID() 等函数,在从库执行时结果可能与主库不同。 |
| ROW | 记录每一行数据被修改成的样子(物理变更)。 | 非常安全,严格保证数据一致性。 | 日志文件非常大(特别是批量 UPDATE 或 DELETE 时),消耗网络 bandwidth。 |
| MIXED | 混合模式。 | 一般用 Statement,遇到可能导致不一致的 SQL(如用到系统变量)时自动切换为 Row。 | 试图平衡两者,但有时难以预测 MySQL 的选择。 |
最佳实践: 目前生产环境(特别是涉及金钱或核心数据时)推荐使用
ROW格式,虽然空间占用大,但能保证数据的绝对一致性。
3. 写入机制 (Append Only)
与 Redo Log 的“循环写”(写满覆盖)不同,Binlog 是追加写(Append Only)。
-
当一个 Binlog 文件写到一定大小(由
max_binlog_size控制)后,会切换创建一个新的文件(例如mysql-bin.000001,mysql-bin.000002)。 -
之前的日志不会被覆盖,除非你手动清理或设置了过期时间。
4. 关键参数:sync_binlog
这个参数控制 Binlog 什么时候刷入磁盘,与性能和安全息息相关:
-
sync_binlog = 0:MySQL 每次将 Binlog 写入 OS Cache,由操作系统决定何时刷盘。性能好,但机器宕机可能丢数据。 -
sync_binlog = 1:每次事务提交都强制刷盘。最安全,但性能损耗最大。 -
sync_binlog = N:每 N 次事务提交刷盘一次。
双 1 配置: 在要求数据严谨的生产环境,通常建议
sync_binlog = 1配合innodb_flush_log_at_trx_commit = 1,这就是常说的“双 1 配置”,能最大程度保证数据不丢失。
5. 再次对比:Redo Log vs Binlog
为了加深记忆,这里再次从另一个角度对比这两个日志:
| 特征 | Redo Log (重做日志) | Binlog (归档日志) |
|---|---|---|
| 生动比喻 | 草稿纸/记事贴 (用完即丢) | 历史档案馆/录像带 (永久保存) |
| 产生者 | InnoDB 引擎特有 | MySQL Server 层 (所有引擎都有) |
| 内容形式 | 物理日志 (“在某页改了某值”) | 逻辑日志 (“执行了某SQL” 或 “某行变为了X”) |
| 主要场景 | 宕机恢复 (Crash Safe) | 主从复制、数据恢复 |
| 事务性 | 事务执行过程中不断写入 | 事务提交时一次性写入 |
6. 一个经典问题:为什么需要两份日志?
你可能会问:既然 Binlog 也有数据记录,为什么 InnoDB 还需要 Redo Log?
-
历史原因: MySQL 最早只有 Binlog(Server层),没有 Crash-safe 能力。后来引入 InnoDB 引擎,InnoDB 为了实现 ACID 中的持久性,自己搞了一套 Redo Log。
-
效率原因: Binlog 是逻辑日志,恢复速度慢(需要重新执行 SQL 或重放行变更);Redo Log 是物理日志,直接映射磁盘位置,恢复速度极快。
介绍一下kafka和RocketMQ的刷盘策略
这是一个非常经典的中间件对比问题。刷盘策略(Flushing Strategy)直接决定了消息队列(MQ)的吞吐量(Performance)和数据可靠性(Reliability)。
Kafka 和 RocketMQ 在这方面的设计理念有明显的区别:
-
RocketMQ: 提供了灵活的选择,由用户决定是追求极致性能还是极致数据安全。
-
Kafka: 倾向于极致的吞吐量,将“数据可靠性”交给多副本复制(Replication)机制,而不是单机的强刷盘。
以下是详细对比:
1. RocketMQ 的刷盘策略
RocketMQ 在 Broker 的配置文件中,通过 flushDiskType 参数提供了两种明确的策略。它的设计思路很像 MySQL 的配置,让用户自己权衡。
A. 异步刷盘 (ASYNC_FLUSH) —— 默认策略
-
机制: 生产者发送消息后,Broker 只要把消息写入内存(Page Cache / MappedByteBuffer)就立刻返回“发送成功”。
-
刷盘时机: 后台有一个线程会定时(通常每隔几毫秒)把内存中的数据刷入磁盘。
-
优缺点:
-
✅ 吞吐量高,延迟低。
-
⚠️ 有数据丢失风险:如果服务器突然断电(宕机),内存中未刷盘的消息会丢失。
-
B. 同步刷盘 (SYNC_FLUSH)
-
机制: 生产者发送消息后,Broker 必须先把消息写入内存,并且强制调用
fsync刷入磁盘后,才返回“发送成功”。 -
优化(Group Commit): 为了不让性能太差,RocketMQ 实现了**Group Commit(组提交)**机制。它不会每来一条消息就刷一次盘,而是攒一小批消息(微秒级等待),一次性
fsync,类似 MySQL 的机制。 -
优缺点:
-
✅ 数据绝对安全,断电不丢数据。
-
⚠️ 吞吐量下降,延迟变高。
-
适用场景: 金融、交易链路等对数据丢失“零容忍”的场景,必须用 SYNC_FLUSH。
2. Kafka 的刷盘策略
Kafka 的设计哲学完全不同。它官方强烈不推荐用户强制控制刷盘,而是把这个工作完全交给操作系统。
A. 异步刷盘 (依赖 OS Page Cache) —— 核心策略
-
机制: Kafka 收到消息后,通过
write()系统调用把数据写入文件系统的 Page Cache(页缓存),然后立刻返回。 -
刷盘时机: Kafka 不主动调用
fsync。它依赖 Linux 系统的后台线程(pdflush/flush)根据系统的脏页策略(vm.dirty_background_ratio等)自动将数据刷入磁盘。 -
为什么这么设计?
-
Kafka 认为在分布式系统中,单机的持久化并不能保证绝对安全(硬盘坏了照样丢)。
-
Kafka 的安全性是通过 多副本机制 (Replication) 来保证的。只要消息被写入了多个副本(ISR 集合),即使主节点宕机且数据未刷盘,数据也可以从其他副本恢复。
-
B. 同步刷盘 (可配置,但很少用)
-
虽然 Kafka 提供了
log.flush.interval.messages(每多少条刷一次)和log.flush.interval.ms(每多少毫秒刷一次)参数,但官方建议保持默认值(即不配置,无限大),交给 OS 管理。 -
频繁调用
fsync会极大地破坏 Kafka 的高吞吐特性。
3. 横向对比总结 (面试必杀技)
| 特性 | RocketMQ | Kafka |
|---|---|---|
| 主要刷盘方式 | 支持同步 & 异步 | 几乎全靠异步 (OS Page Cache) |
| 配置参数 | flushDiskType (SYNC_FLUSH / ASYNC_FLUSH) |
log.flush.interval (建议忽略) |
| 数据安全性保障 | 单机层面:靠同步刷盘保证。 集群层面:靠主从复制。 |
完全依赖集群层面的副本复制机制 (Replication / ISR)。 |
| 设计哲学 | 像传统数据库,提供“金融级”的单机可靠性选项。 | 追求极致吞吐,相信操作系统和集群副本。 |
| 性能 | 异步刷盘极快;同步刷盘较慢(但有组提交优化)。 | 极快(因为本质上是写内存)。 |
4. 深度思考:为什么 Kafka 敢不刷盘?
这往往是面试官的追问:“Kafka 异步刷盘,万一掉电了怎么办?”
回答的关键在于 acks 参数:
-
如果设置
acks=all(或-1):-
Kafka 会确保消息不仅写入了 Leader 的内存,还同步到了所有 ISR(In-Sync Replicas)节点的内存中,才会告诉生产者“成功”。
-
容灾逻辑: 即使 Leader 突然断电且未刷盘,只要集群中还有一个 ISR 节点活着,数据就不会丢。
-
结论:
-
RocketMQ 的同步刷盘是物理层面的(写进硬盘才算完)。
-
Kafka 的安全是逻辑层面的(复制到多台机器的内存才算完)。
Page Cache是什么?
简单一句话总结:Page Cache(页缓存)就是操作系统拿出一部分内存(RAM),专门用来给硬盘(Disk)“加速”的。
我们从“在哪里”和“干什么”两个方面来拆解:
1. 存储在哪里?
它就在你的内存条里(RAM)。
Page Cache 不是什么特殊的硬件,也不是硬盘里的一部分。
-
当你买了一台服务器,比如有 32GB 内存。
-
你的 Java 程序只用了 4GB。
-
剩下的 28GB 内存闲着也是闲着,操作系统(Linux)就会毫不客气地把这些空闲内存征用,当作 Page Cache 使用。
注意: 它是易失性的。既然是在内存里,一旦断电或者重启,Page Cache 里的东西瞬间就没了。
2. 它是干啥的?(为什么要用它?)
核心原因只有一个:硬盘太慢了,内存太快了。
-
内存(RAM) 的速度像法拉利。
-
硬盘(Disk) 的速度像蜗牛。
如果 CPU 每次读写数据都要等着硬盘(蜗牛)慢慢爬,那 CPU(法拉利)大部分时间都在“发呆”等待。为了解决这个速度不匹配的问题,Linux 引入了 Page Cache 当作“中间商”。
A. 写操作(Write)的加速: “骗”你写完了
当 Kafka 说“我要把消息写到硬盘”时:
-
操作系统直接把数据丢进 Page Cache(内存)。
-
操作系统立刻告诉 Kafka:“写完了,你走吧!”(其实还没进硬盘)。
-
结果: Kafka 觉得写硬盘飞快(其实是写了内存),吞吐量极高。
-
后续: 操作系统会在后台,找个空闲时间,慢慢把 Page Cache 里的数据搬运到硬盘里(这个过程叫 Flush/刷盘)。
比喻: 你去图书馆还书(写数据)。 如果没有 Page Cache,你得自己跑进库房把书插回架子上(写磁盘),很慢。 有了 Page Cache,前台放了一个还书箱(内存),你把书往箱子里一扔就走了(瞬间完成)。管理员晚点再把箱子里的书摆回架子。
B. 读操作(Read)的加速: “猜”你会再用
当你要从硬盘读取一个文件时:
-
操作系统把文件从硬盘读出来。
-
先在 Page Cache(内存) 里留一份备份,然后再给你。
-
结果: 下次你(或者别人)再来读同一个文件时,操作系统直接从内存里拿给你,完全不需要动硬盘。速度提升几百倍。
3. 一个直观的现象(Linux 内存占用)
很多新手在用 Linux 时会发现一个“奇怪”的现象:
-
我看机器空闲着,没跑什么程序。
-
但用
free命令一看,内存(Memory)怎么被占用了 90% 以上?
原因就是 Page Cache。 Linux 的逻辑是:“闲着的内存就是浪费”。与其空着,不如把所有读写过的文件都缓存起来。
- 如果你的程序突然需要内存怎么办? 放心,Linux 会瞬间释放掉一部分 Page Cache 腾出空间给你的程序用。它是“借用”,不是“霸占”。
4. 总结
回到 Kafka 和 MySQL 的场景:
-
Page Cache 是谁? 是 Linux 操作系统利用空闲内存构建的一层缓存。
-
在哪里? 在内存条里(RAM)。
-
Kafka 为什么快? 因为 Kafka 写数据实际上是写到了 Page Cache(内存)里,相当于写内存,当然快。
-
风险是什么? 既然在内存里,断电即失。
-
这就是为什么 Kafka 叫“异步刷盘”(写完内存就算成功)。
-
这也是为什么 MySQL 为了安全要搞“同步刷盘”(必须从 Page Cache 逼到硬盘里才算成功)。
-