面试题总结
HashMap的底层原理
Hashap 是基于哈希表的数据结构,用于存储键值对(key-value )。其核心是将键的哈希值映射到数组索引位置,通过数组 +链表(在 Java 8 及之后是数组 +链表 +红黑树)来处理哈希冲突。
Hashmap 的默认初始容量为 16,负载因子为 0.75。也就是说,当存储的元素数量超过16x0.75=12个时, Hashmap 会触 发扩容操作,容量x2并重新分配元素位置。这种扩容是比较耗时的操作,频繁扩容会影响性能。
HashMap 的红黑树优化:
从Java8开始,为了优化当多个元素映射到同一个哈希桶(即发生哈希冲突)时的查找性能,当链表长度超过8时,链表会转变为红黑树。红黑树是一种自平衡二叉搜索树,能够将最坏情况下的査找复杂度从 O(n) 降低到 O(log n)。如果树中元素的数量低于 6,红黑树会转换回链表,以减少不必要的树操作开销。
hashCode()和 equals()的重要性:
HashMp 的键必须实现 hashcode()和 equals()方法。 hashcode()用于计算哈希值,以决定键的存储位置,而 equals()用于比较两个键是否相同。在 put 操作时,如果两个键的 hashcode()相同,但 equals()返回 false,则这两个键会被视为不同的键,存储在同一个桶的不同位置。
经典的“哈希冲突”案例
在 Java 中,最著名的例子就是字符串 "Aa" 和 "BB"。
Java
|
|
发生了什么?
Java 字符串的哈希算法是 s[0]*31 + s[1]:
-
'A'是 65,'a'是 97 \rightarrow 65 \times 31 + 97 = 2112 -
'B'是 66 \rightarrow 66 \times 31 + 66 = 2112
虽然算出来的数字一样,但显然 "Aa" 和 "BB" 是完全不同的字符串。
HashMap成环
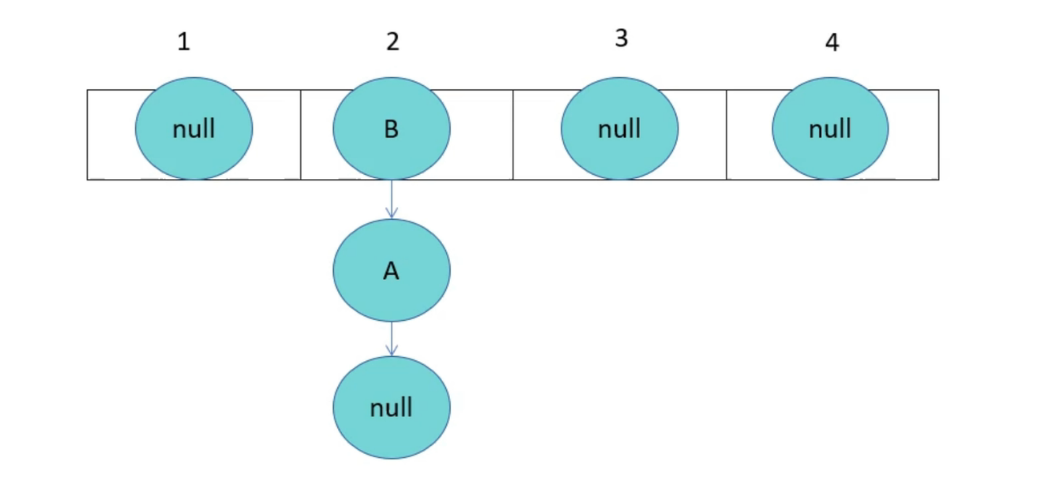
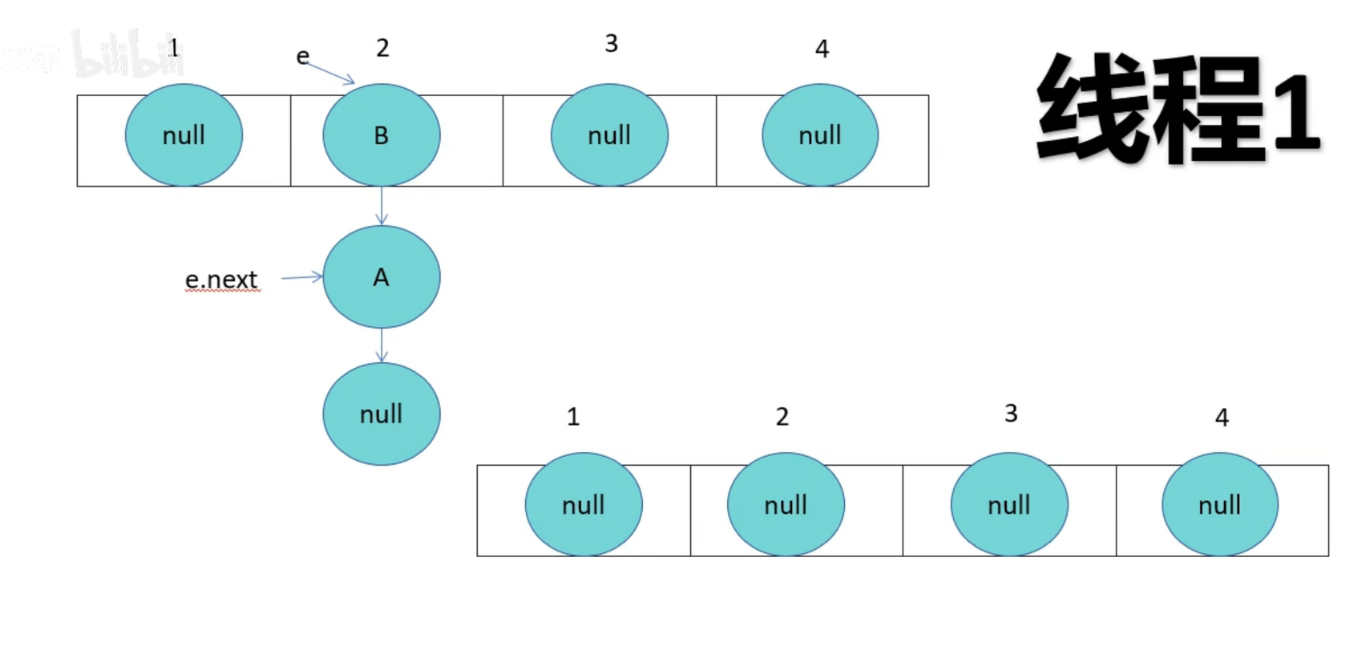
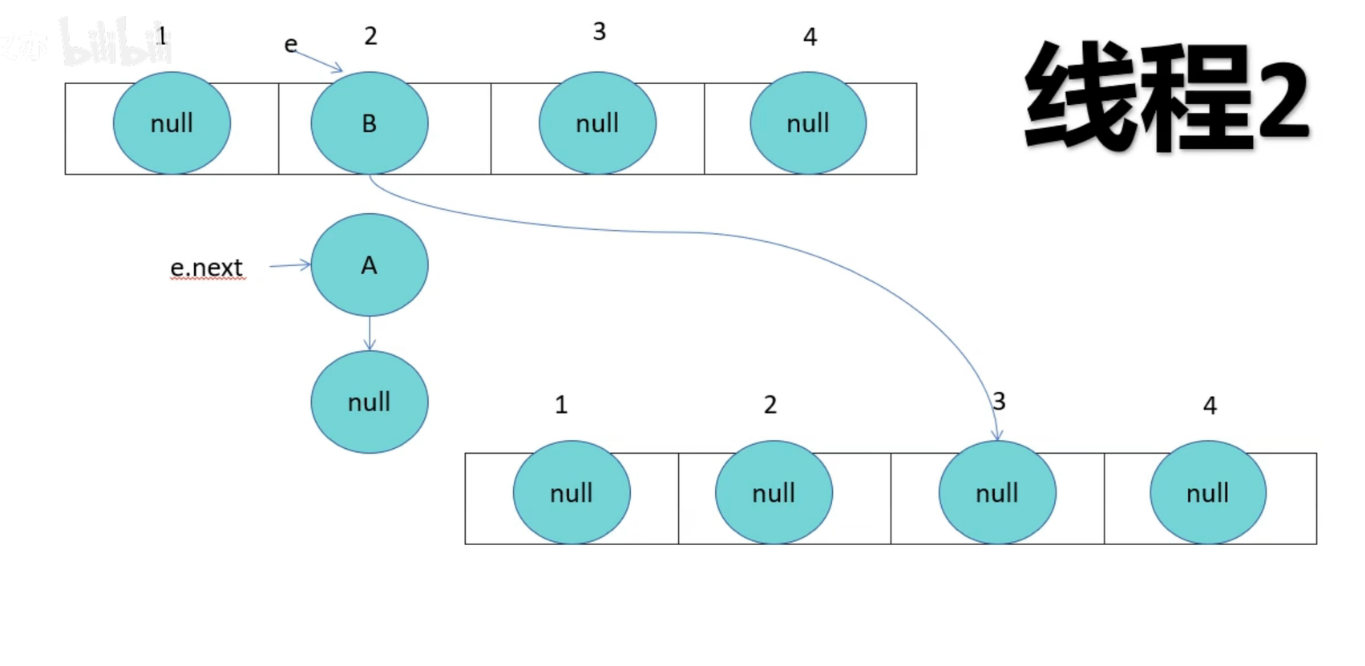
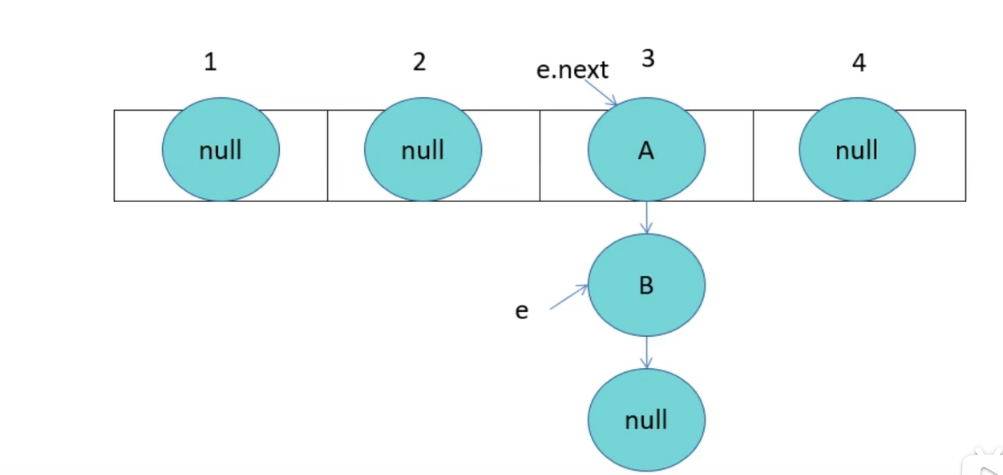
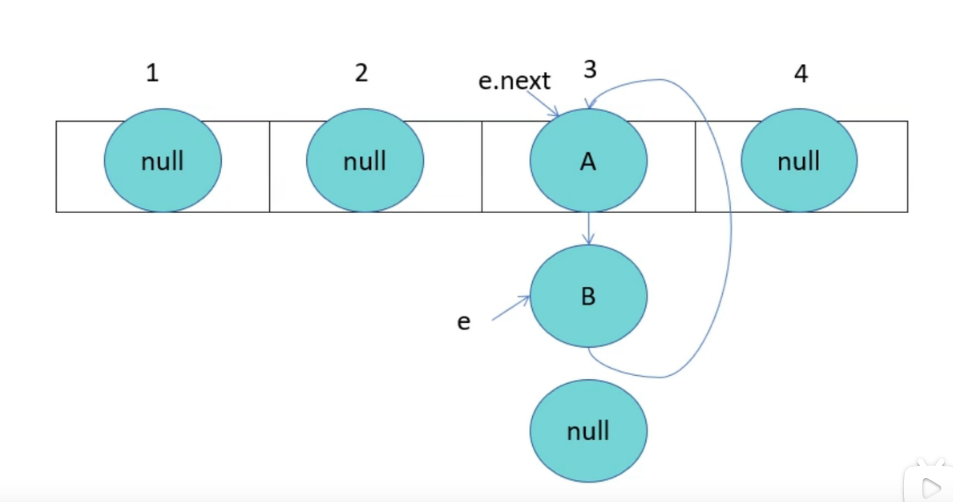
由于线程1已经指向了B和A,线程2却先一步执行了扩容操作,而停止循环的条件就是e.next为null,当执行完扩容后,线程1苏醒,此时e为B,e.next为A,当前e的next指向A,导致A与B之间产生死循环,颠倒后依旧产生连接,就形成了环。
JDK1.7HashMap多线程死循环问题_哔哩哔哩_bilibili
Synchronized 和 ReentrantLock有什么区别?
实现层面
synchronized:
- 是 Java 的关键字,属于 JVM 层面的实现。
ReentrantLock:
- 是 JDK 提供的一个类(
java.util.concurrent.locks.ReentrantLock),属于 API 层面的实现。
锁的释放
synchronized:
- 自动释放。代码执行完同步代码块,或者抛出异常时,JVM 会自动释放锁,不会导致死锁。
ReentrantLock:
- 手动释放。必须手动调用
unlock()方法。
锁的公平性
synchronized:
- 只能是非公平锁。线程获取锁的顺序是不确定的,可能发生“饥饿”现象。
ReentrantLock:
-
默认是非公平锁(性能更好)。
-
可以通过构造函数
new ReentrantLock(true)指定为公平锁(遵循先来后到原则),但性能会下降。
等待可中断
synchronized:
- 不可中断。如果一个线程正在等待获取锁,它不能被中断(
interrupt),只能一直阻塞等待。
ReentrantLock:
- 可中断。通过
lockInterruptibly()方法,可以让正在等待锁的线程响应中断,放弃等待去处理其他事情。
尝试获取锁
synchronized:
- 不行。要么拿到锁,要么阻塞死等。
ReentrantLock:
- 提供
tryLock()方法。可以尝试获取锁,如果锁被占用,可以选择立即返回false或者等待一段指定的时间,非常灵活。
| 特性 | synchronized(隐式锁) | ReentrantLock(显式锁) |
|---|---|---|
| 实现方式 | 关键字 (JVM 层面) | 类 (JDK API 层面) |
| 锁的释放 | 隐式自动释放 | 显式手动释放 (需在 finally 中 unlock) |
| 公平性 | 非公平 | 默认非公平,可设置为公平 |
| 响应中断 | 不支持 | 支持 (lockInterruptibly) |
| 条件队列 | 单个 (wait/notify) | 多个 (Condition) |
| 尝试获取 | 不支持 (死等) | 支持 (tryLock) |
| 灵活性 | 低 | 高 |
锁升级
锁升级流程图解
| 锁状态 | 触发条件 | 优点 | 缺点 |
|---|---|---|---|
| 偏向锁 | 只有一个线程反复加锁 | 加锁/解锁几乎零消耗 | 如果存在线程竞争,撤销偏向锁会有额外开销 |
| 轻量级锁 | 线程交替执行,无同时竞争 | 不会阻塞线程,利用 CAS 和自旋,响应速度快 | 如果始终得不到锁,自旋会空耗 CPU |
| 重量级锁 | 发生长时间或多线程同时竞争 | 不会空耗 CPU,未获锁线程进入阻塞 | 线程阻塞/唤醒涉及上下文切换,开销大,较慢 |
CAS与自旋
什么是CAS(乐观锁)
-
你看到原句是“Hello”(A)。
-
你想改成“Hi”(B)。
-
在你提交修改的一瞬间,系统检查文档当前还是不是“Hello”(V)。
-
如果是,修改成功。
-
如果文档已经被别人改成了“Hello World”,你的预期(A)和实际(V)不符,提交失败,你需要重新读取再尝试。
-
CAS 的三大问题
-
ABA 问题(最著名的坑):
-
虽然 V 还是 A,但不代表它没变过。它可能经历了
A -> B -> A的过程。 -
比喻:桌上有一杯水(A),你离开了一会儿。回来时水还是满的(A),你以为没人动过。实际上可能有人喝光了(B),又给你倒满了(A)。虽然结果一样,但过程可能由于“杯子被用过”而产生副作用。
-
解决:加版本号。变成
1A -> 2B -> 3A。Java 中的AtomicStampedReference就是干这个的。给提交结果加版本号
-
-
只能保证一个变量的原子性:无法同时操作多个变量。
-
CPU 开销大:这通常与“自旋”结合在一起,见下文。
什么是 自旋 ?
自旋是一种线程等待的策略。
当线程抢不到锁(或 CAS 失败)时,它不放弃 CPU,不进入阻塞状态(不睡觉),而是执行一个空循环(Loop),不断地检查“锁释放了吗?”或者“我能重试 CAS 了吗?”。
为什么要自旋?
为了避免上下文切换的开销。
-
阻塞/唤醒:线程挂起和恢复需要操作系统介入,保存和恢复现场,非常耗时(可能比执行代码本身还慢)。
-
自旋:如果锁被占用的时间很短,我在门口转两圈(自旋)锁就释放了,这样比“回家睡觉再被电话叫醒”快得多。
| 概念 | 作用 | 核心词 | 优缺点 |
|---|---|---|---|
| CAS | 实现原子更新 | 比较并交换 | 优点:非阻塞,性能好 缺点:ABA 问题 |
| 自旋 | 等待锁的策略 | 循环重试 | 优点:避免上下文切换 缺点:耗费 CPU |
SpringBean的生命周期
阶段一:创建与注入 (的基础)
1. 实例化 (Instantiation)
-
发生了什么: Spring 容器通过反射(
Constructor.newInstance())调用 Bean 的构造函数。 -
状态: 此时对象已经在堆内存中存在了,但它只是一个“空壳子”,里面的属性(依赖)全是
null。 -
类比: 刚买了一个毛坯房,房子建好了,但里面什么家具都没有。
2. 属性赋值 (Populate Properties)
-
发生了什么: Spring 依据配置(XML 或
@Autowired、@Value),将依赖的对象或属性值注入到 Bean 中。 -
状态: 对象内部的依赖已经填充完毕。
-
类比: 装修工进场,把沙发(Service)、电视(Dao)都搬进了房子里。
阶段二:容器感知 (Aware 接口回调)
3. Aware 接口回调 (Invoke Aware Interfaces)
- 发生了什么: 如果 Bean 实现了特定的
Aware接口,Spring 会把容器内部的一些资源“告诉”这个 Bean。
阶段三:初始化与增强 (最关键的步骤)
所谓的“初始化阶段”,就是 Spring 给你一个机会,在“属性都装好了”之后,但在“给别人使用”之前,让你执行一段自己的业务代码(比如连数据库、加载缓存、校验配置)。
Spring AOP(默认机制)使用的是 动态代理(Dynamic Proxy)。它的逻辑是委托(Delegation)。
-
原本的流程:
调用者 \rightarrow 目标对象(Target)
-
Spring AOP 的流程:
调用者 \rightarrow 代理对象(Proxy) \rightarrow 执行增强代码(Before) \rightarrow 调用目标对象 \rightarrow 执行增强代码(After) \rightarrow 返回
| 特性 | Spring AOP | AspectJ(静态代理) |
|---|---|---|
| 原理 | 动态代理 (Proxy) | 字节码织入 (Bytecode Weaving) |
| 修改方式 | 运行时生成新类包裹目标 | 编译期/加载期直接修改目标类字节码 |
| 是否需要接口 | JDK模式需要,CGLIB不需要 | 不需要 |
| 性能 | 稍慢(有反射和代理调用的开销) | 极快(就是普通的方法调用) |
| 能力范围 | 只能拦截 public 方法 的调用 | 无所不能:可拦截 private 方法、静态方法、构造函数、字段访问等 |
| 内部调用(this) | 失效 | 有效 (完美解决自调用问题) |
| 复杂度 | 低(Spring Boot 开箱即用) | 高(需要配置编译器或 JVM Agent) |
Redis和Memcached的区别
| 特性 | Memcached | Redis |
|---|---|---|
| 数据结构 | 单一 (仅支持 String/二进制块) | 丰富 (String, List, Hash, Set, ZSet, Bitmap, HyperLogLog, Stream, Geo) |
| 线程模型 | 多线程 (Multi-threaded) | 单线程 (主逻辑) + I/O 多线程 (Redis 6.0+) |
| 持久化 | 不支持 (重启后数据丢失) | 支持 (RDB 快照 & AOF 日志) |
| 分布式支持 | 客户端实现 (服务端互不通信) | 服务端支持 (Redis Cluster, Sentinel) |
| 内存管理 | Slab Allocation (预分配,无碎片,但在非均匀大小数据下有浪费) | jemalloc/libc (按需分配,利用率高,但可能有内存碎片) |
| 功能丰富度 | 仅缓存 | Lua 脚本、发布/订阅 (Pub/Sub)、事务、Pipeline |
| 最大值限制 | Value 最大 1MB | Value 最大 512MB |
A. 数据类型 (Data Types) —— 最大的区别
-
Memcached: 就像一个巨大的
Map<String, String>。如果你想存一个列表,必须先把列表序列化成 JSON 字符串存进去;取出来时,必须把整个字符串取出来反序列化,修改后再序列化存回去。这非常消耗网络带宽和 CPU。 -
Redis: 就像一个瑞士军刀。你可以直接在服务端操作数据结构。
-
例子: 你想给一个排行榜加分。
-
Redis:
ZINCRBY rank_list 10 "user_id"(直接在内存里改数值,极快)。 -
Memcached:
get-> 反序列化 ->value + 10-> 序列化 ->set(并发下还需要加锁,否则数据不一致)。
-
B. 线程模型 (Threading Model) —— 性能的分水岭
-
Redis (单线程为主):
-
Redis 的核心操作(执行命令)是单线程的。
-
优势: 没有线程切换开销,没有锁竞争(Lock-free),代码简单稳定。
-
劣势: 无法利用多核 CPU 的优势(但在 6.0 版本引入了多线程 I/O 来处理网络读写,核心计算依然是单线程)。
-
-
Memcached (多线程):
-
它使用主线程监听端口,Worker 线程处理读写。
-
优势: 可以轻松利用 64 核 CPU 的计算能力,在极高并发(数十万 QPS 以上)且 Value 很小 的场景下,吞吐量可能高于 Redis。
-
C. 持久化 (Persistence) —— 数据安全性
-
Memcached: 把它当作一个易失性缓存。如果服务器断电或重启,所有缓存数据瞬间清空,数据库会瞬间面临巨大的“缓存击穿”压力。
-
Redis: 支持持久化。
-
RDB: 定期生成快照保存在磁盘。
-
AOF: 记录每一条写命令。
-
用途: 重启后可以自动恢复数据,甚至可以用来做主数据库使用。
-
D. 分布式/集群 (Clustering)
-
Memcached: 服务端是“傻瓜式”的,节点之间互不通信。分布式的逻辑完全由客户端(Client)控制(通常使用一致性哈希算法)。如果你加一台服务器,客户端需要重新计算哈希。
-
Redis: 支持原生的 Redis Cluster。服务端之间会通信(Gossip 协议),支持自动分片、故障转移(Failover)。
内核内存 vs. 用户内存 (The Two Worlds)
操作系统(如 Linux)为了安全和稳定,把内存划分成了两个隔离的区域:
1. 内核内存 (Kernel Memory / Kernel Space)
-
权限: 最高权限 (Ring 0)。CPU 可以执行任何指令,访问任何硬件地址。
-
居住者: 操作系统内核代码、驱动程序(网卡驱动)、硬件缓冲区。
-
特点: 如果这块区域的代码崩溃了,整个操作系统就蓝屏或死机了。它是神圣不可侵犯的。
2. 用户内存 (User Memory / User Space)
-
权限: 受限权限 (Ring 3)。只能访问自己的内存空间,严禁直接访问硬件(不能直接读写网卡、硬盘)。
-
居住者: 你运行的应用程序(Redis, Java JVM, 浏览器, QQ)。
-
特点: 如果你的 Redis 崩了,只是这一个进程死掉,操作系统照样运行。
核心矛盾: 网卡收到的数据首先必须存放在内核内存(因为它是由驱动程序管理的)。但是,你的 Redis 运行在用户内存。
代价: 数据必须从“内核态”拷贝 (Copy) 到“用户态”,应用程序才能处理。这就是 Redis 6.0 引入多线程 I/O 想要优化的那个“搬运”过程。###
Socket 是什么? (The Abstraction)
很多初学者认为 Socket 就是“插座”或者“连接”。在操作系统层面,Socket 本质上是内核内存中的两个缓冲区(Buffer)。
当你创建一个 Socket(比如 Java 的 new Socket() 或 Redis 监听的端口),内核会在内核内存里为你申请两块地:
-
接收缓冲区 (Recv Buffer): 存放网卡发过来、等待你读取的数据。
-
发送缓冲区 (Send Buffer): 存放你写进去、等待网卡发送的数据。
Socket 就是应用程序(用户态)和网络协议栈(内核态)交互的句柄 (File Descriptor)。
Redis数据的全生命周期流程
假设外网发来一个 TCP 包给 Redis(端口 6379),流程如下:
1. 物理层:网卡收货 (NIC)
-
网线传来电信号,网卡将其转换为二进制数据。
-
DMA (Direct Memory Access): 网卡不经过 CPU,直接利用 DMA 技术,把数据包写入到 内核内存 中的一块公用区域(通常叫 Ring Buffer)。
-
此时,数据在内核,但还不知道属于哪个 Socket。
2. 链路层 & 网络层:内核协议栈介入
-
网卡给 CPU 发送中断 (Interrupt)。
-
CPU 停下手中的活,运行网卡驱动程序。
-
驱动程序把数据包包装成内核的数据结构(Linux 下叫
sk_buff)。 -
操作系统检查 IP 头:是发给本机的吗?是的。
3. 传输层:分发给 Socket (Demultiplexing)
-
操作系统检查 TCP 头:目标端口是 6379。
-
内核查找:“哪个 Socket 正在监听 6379 端口?” -> 找到了 Redis 的那个 Socket。
-
关键动作: 内核把这个数据包(
sk_buff)挂到该 Socket 的接收缓冲区 (Recv Buffer) 队列的尾部。 -
此时,数据依然在内核内存中,但已经归属到了特定的 Socket 名下。
4. 应用层:数据搬运 (Copy to User)
-
Redis 主线程(或 I/O 线程)调用系统函数
read(socket_fd)。 -
CPU 发生上下文切换: 从用户态切入内核态。
-
内存拷贝: CPU 把数据从 内核内存(Socket 的接收缓冲区) 复制到 用户内存(Redis 定义的 buffer)。
-
Redis 终于拿到了数据,开始解析处理
set name ...。
那 Redis 6.0 的 I/O 线程到底解决了什么?
既然都要经过内核拷贝,那用主线程调 write 和用 I/O 线程调 write 有什么区别?
区别在于“谁在等”和“谁在分担开销”。
场景:如果你只有主线程(Redis < 6.0)
-
主线程:“我要处理 10,000 个客户端的
get请求。” -
对于每一个请求,主线程都要亲自调用
write。 -
每次
write,主线程都要经历:用户态->内核态切换 (耗时) + CPU 搬运数据 (耗时) + 内核态->用户态切换 (耗时)。 -
结果: 主线程大量时间花在和内核打交道、等待搬运上,导致它处理命令(KV 读写)的时间变少了。
场景:你有 I/O 线程(Redis 6.0+)
-
主线程:“我要处理 10,000 个请求。算出结果后,我不亲自发了。”
-
主线程把结果扔给 4 个 I/O 线程,说:“你们去调
write发给客户。” -
主线程立刻转头去处理下一个命令的计算(KV 读写)。
-
I/O 线程们 并行地去调用
write,去承担上下文切换和 CPU 搬运数据的开销。 -
结果: 主线程被解放了,只专注于纯内存计算,吞吐量大增。
内核线程,内核级线程,用户级线程
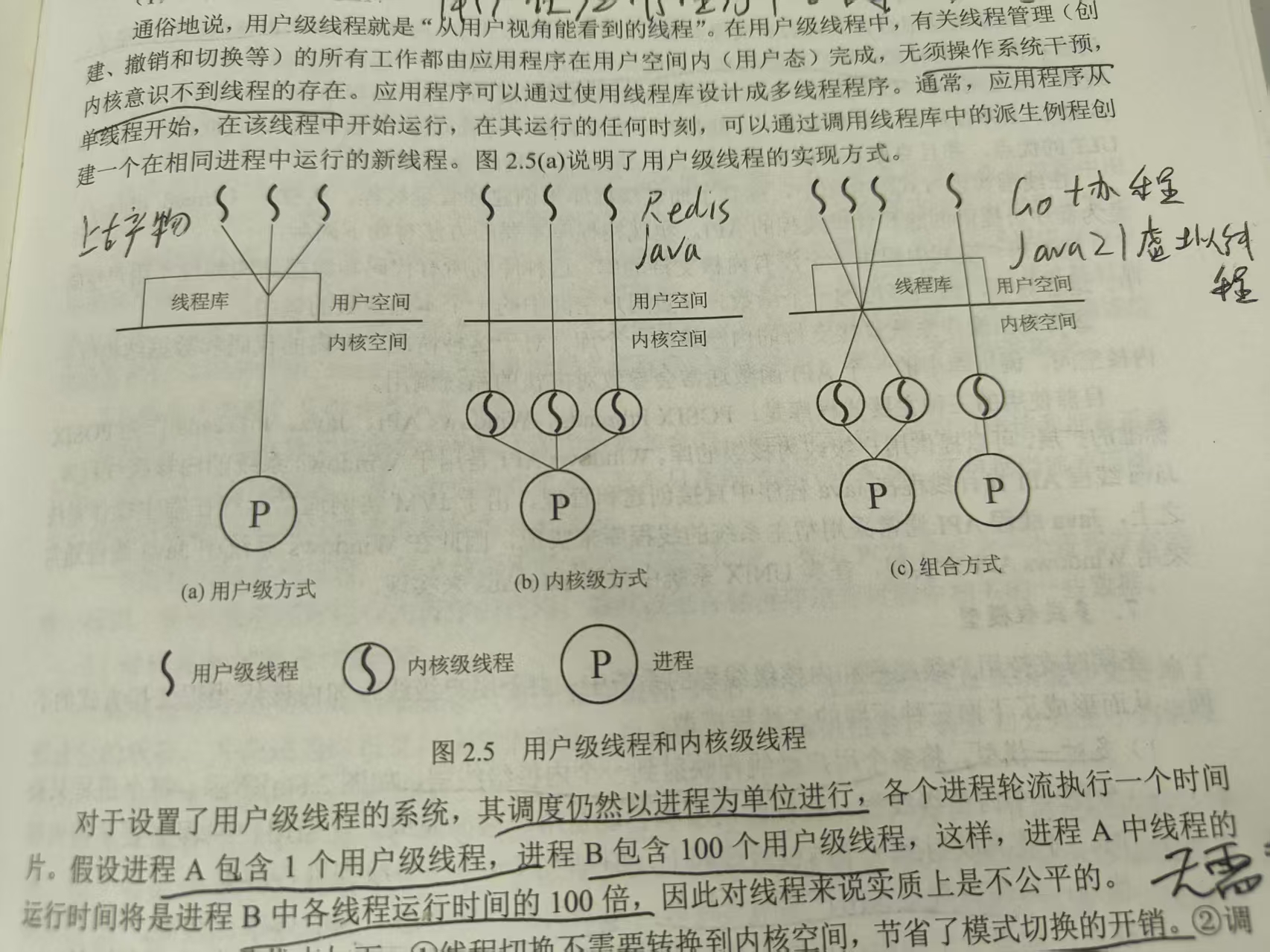
用户级线程是怎么“骗”过内核的?(M:N 模型)
用户级线程通过一个**中间层(Runtime/Scheduler)**来实现。
-
M 个用户级线程(比如 1000 个 Goroutine)。
-
N 个内核级线程(通常等于 CPU 核数,比如 8 个)。
-
映射关系:
-
这 8 个内核线程是“干活的苦力”。
-
这 1000 个协程是“待办的任务”。
-
Go 语言的运行时(Runtime)负责把这 1000 个任务,源源不断地塞给这 8 个苦力去做。
-
如果一个任务(协程)卡在 I/O 上了,Runtime 把它拿开,换一个新任务给苦力,苦力(内核线程)永远不休息,也永远不阻塞。
-
我们可以把计算机系统看作一家大型工厂(操作系统):
-
内核线程 (Kernel Thread): 工厂的内部设施维护人员(只在核心区工作,不生产对外产品)。
-
内核级线程 (Kernel-Level Thread, KLT): 工厂正式聘用的流水线工人(有工牌,受人事部直接管理)。
-
用户级线程 (User-Level Thread, ULT): 包工头带来的临时工/外包团队(人事部不知道他们的存在,只知道包工头)。
一、 详细拆解:三者的定义与区别
1. 内核线程 (Kernel Thread / kthread)
这是最底层的存在,它们完全运行在内核空间(Ring 0)。
-
定义: 它是操作系统内核用来执行后台任务的线程。它没有用户地址空间(不映射用户内存),只能访问内核代码和数据。
-
谁创建/管理: 操作系统内核。
-
能干啥:
-
将内存中的脏页刷写到磁盘(如 Linux 的
kflush或pdflush)。 -
处理软中断和网络包(如
ksoftirqd)。 -
执行磁盘 I/O 调度。
-
-
特点: 也就是我们常说的“纯内核线程”。你在 Linux 用
ps -ef看到的那些名字带中括号[kthreadd]、[migration]的进程,就是它们。 -
与用户程序的关系: 完全没关系。它们不运行你的 Java 或 Redis 代码,它们只服务于 OS 本身。
2. 内核级线程 (Kernel-Level Thread, KLT)
这是我们日常开发中最常接触的概念(虽然你可能没意识到)。 在 Linux 中,它们通常被称为 轻量级进程 (LWP, Light Weight Process)。
-
定义: 这是一个由内核管理、但用于执行用户态代码的执行实体。它是**“用户进程”在内核眼里的分身**。
-
谁创建/管理: 操作系统内核调度器(如 CFS)。
-
能干啥: 执行你的
main()函数,执行 Redis 的主逻辑,执行 Java 的线程。 -
特点:
-
拥有双重身份: 既有内核栈(陷入内核时用),也有用户栈(运行程序时用)。
-
可被独立调度: 操作系统知道它的存在,可以将它分配给任意 CPU 核心。
-
高开销: 创建、销毁、切换都需要系统调用,涉及内核态/用户态切换,成本较高(微秒级)。
-
-
代表: Java 的
java.lang.Thread(在 Linux 上),C++ 的std::thread,Redis 的主线程和 I/O 线程。
3. 用户级线程 (User-Level Thread, ULT)
也叫协程、纤程、Green Thread。
-
定义: 完全在用户空间实现的线程机制。内核完全不知道它们的存在,内核只看到承载它们的那个 KLT。
-
谁创建/管理: 编程语言的运行时(Runtime)或库(如 Go Runtime, JVM)。
-
能干啥: 处理高并发逻辑,阻塞式写法的异步执行。
-
特点:
-
极轻量: 切换只涉及寄存器保存,无需陷入内核,纳秒级。
-
不可独立调度: 操作系统无法直接把一个 ULT 分配给 CPU,必须依附于一个 KLT 才能运行。
-
-
代表: Go 的 Goroutine, Python 的 Gevent, Java 21 的 Virtual Thread。
二、 它们之间的映射模型 (The Mapping Models)
弄清楚关系的关键,在于理解用户级线程 (ULT) 和 内核级线程 (KLT) 是如何搭配工作的。这主要有三种模型:
1. 多对一模型 (M : 1) —— 上古时代的产物
-
描述: 多个用户级线程(M)跑在 1 个内核级线程(1)上。
-
例子: 老版本的 Python 异步库,某些老旧的 JVM 实现(Green Threads)。
-
缺点: 没有并行能力。因为底层只有一个 KLT,所以一次只能用 1 个 CPU 核。如果其中一个 ULT 阻塞了(比如发起系统调用),底层的 KLT 就阻塞了,其他所有 M 个 ULT 全都卡死。
2. 一对一模型 (1 : 1) —— 现代主流 (Redis, Nginx, Java)
-
描述: 1 个用户级线程(逻辑上的线程)直接对应 1 个内核级线程。
-
机制: 当你在 Java 里
new Thread(),操作系统就在底层真的创建一个 KLT(LWP)。 -
优点: 真正的并行。一个线程阻塞,不影响其他线程。实现简单,直接依赖 OS 调度。
-
缺点: 线程太贵,开不了一百万个。
-
现状: Redis 的主线程和 I/O 线程,Java 目前默认的线程模型,都是 1:1。 所谓的“用户线程”此时只是 KLT 的一个句柄。
3. 多对多模型 (M : N) —— 高并发的未来 (Go,Java21 Virtual Threads)
-
描述: M 个用户级线程(协程)动态映射到 N 个内核级线程上。
-
机制:
-
Runtime 维护一个线程池(N 个 KLT)。
-
Runtime 维护一个任务队列(M 个 ULT)。
-
Runtime 负责把 ULT 喂给 KLT 执行。如果一个 ULT 阻塞了,Runtime 把它拿下来,换另一个 ULT 上去。
-
-
优点: 既有 ULT 的轻量(可以开百万个),又有 KLT 的并行(利用多核 CPU)。
-
现状: Go 语言之所以火,就是因为它的调度器(G-M-P 模型)把这个做到了极致。
三、 总结与对比表
| 特性 | 内核线程 (Kernel Thread) | 内核级线程 (KLT / LWP) | 用户级线程 (ULT / Coroutine) |
|---|---|---|---|
| 可见性 | 仅内核可见 | 内核可见,用户可见 | 仅用户程序可见 (内核不可见) |
| 内存空间 | 仅内核空间 | 用户空间 + 内核空间 | 仅用户空间 |
| 调度者 | OS 调度器 | OS 调度器 | 语言运行时 (Runtime) |
| 切换开销 | 小 (无需切换地址空间) | 中 (需切入内核态) | 极小 (纯用户态操作) |
| 并行性 | 利用多核 | 利用多核 | 依赖于底层的 KLT |
| 阻塞影响 | - | 线程阻塞,释放 CPU 给别人 | 协程阻塞,Runtime 切换其他协程 |
| 典型例子 | ksoftirqd, kworker |
java.lang.Thread, Redis 线程 |
Go Goroutine, Java Virtual Thread |
一般什么情况下需要陷入内核态?
简单来说,“陷入内核态”(Trap into Kernel Mode) 也就是 CPU 从 特权级 3 (User Ring 3) 切换到 特权级 0 (Kernel Ring 0) 的过程。
一般情况下,陷入内核态主要有且仅有三种场景:
1. 系统调用 (System Call) —— 主动请求
这是最常见的情况。当你的程序需要做一些自己权限不够的事情时,必须主动向操作系统“打报告”。
因为用户程序不能直接操作硬件(硬盘、网卡、声卡)或管理内存,必须通过特定的接口(System Call Interface)请求内核代劳。
-
硬件 I/O 操作:
-
读写文件:
read(),write(),open()(Redis 写日志、读数据库)。 -
网络通信:
socket(),connect(),send(),recv()(Redis 处理请求)。 -
屏幕输出:
printf()(底层调用write输出到标准输出)。
-
-
进程控制:
-
创建进程:
fork(),exec()(Redis 做 RDB 快照时会 fork 子进程)。 -
退出程序:
exit()。
-
-
内存管理:
- 申请内存:
malloc()在堆内存不够时,底层会调用brk()或mmap()向内核要内存。
- 申请内存:
比喻: 你要去银行取钱(操作硬件资源),你不能自己冲进金库拿,必须填单子(系统调用),交给柜员(内核),柜员帮你拿出来给你。
2. 异常 (Exception) —— 内部错误或特殊事件
这是由 CPU 在执行指令时,内部检测到的意外情况。程序“闯祸了”或者遇到了“特殊指令”。
-
缺页异常 (Page Fault):
- 当你访问一块内存地址,CPU 发现这块数据不在物理内存里(可能被换到了磁盘 swap 分区,或者刚申请还没分配物理页),CPU 会暂停程序,陷入内核。内核负责把数据从磁盘加载到内存,然后恢复程序运行。
-
程序错误:
-
除以零: 代码里写了
100 / 0。 -
非法内存访问 (Segfault): 试图访问不属于你的内存地址(比如空指针解引用)。
-
内核捕获这些错误后,通常会杀死进程(就是你看到的
Segmentation fault)。
-
-
调试断点:
- 当你用 GDB 调试代码打断点时,实际上是插入了一条特殊指令(如 x86 的
INT 3)。CPU 执行到这里会自动陷入内核,暂停程序,把控制权交给调试器。
- 当你用 GDB 调试代码打断点时,实际上是插入了一条特殊指令(如 x86 的
比喻: 你在家里(用户态)做饭,突然锅炸了(除以零)或者你想进邻居家里(非法内存访问),这时候警察(内核)会立刻破门而入处理状况。
3. 硬件中断 (Hardware Interrupt) —— 被动打断
这是来自 CPU 外部的信号。无论你的程序正在干什么,只要硬件中断来了,CPU 必须无条件停下手头的工作,切到内核态去处理中断。
-
时钟中断 (Clock Interrupt):
-
最重要! 这是多任务操作系统的基石。
-
硬件时钟每隔几毫秒就会发一次中断。内核收到中断后,会看:“Redis,你的时间片用完了,该让给 Nginx 跑一会儿了。”
-
这就是为什么死循环的程序不会把电脑彻底卡死,因为内核会强行通过时钟中断夺回控制权。
-
-
I/O 完成中断:
-
网卡: “新数据包到了!”(内核把数据拷贝到 Socket 缓冲区)。
-
硬盘: “刚才你要读的数据我已经读完放到内存了!”
-
-
键盘/鼠标输入:
- 你按下一个键,键盘控制器发送中断,CPU 陷入内核读取按键码。
比喻: 你正在家里专心打游戏(用户态运行代码),突然快递员狂按门铃(网卡中断),或者你的闹钟响了(时钟中断),你必须停下游戏去开门或者关闹钟(陷入内核处理)。
| 触发方式 | 来源 | 例子 | 主动/被动 |
|---|---|---|---|
| 系统调用 | 程序代码 | read(), fork(), sleep() |
主动 (程序自己写的) |
| 异常 | CPU 内部 | 缺页、除零、Segfault | 被动 (通常是闯祸了) |
| 硬件中断 | CPU 外部 | 网卡收包、时钟滴答、键盘 | 被动 (外部环境强制) |
Redis单线程避免上下文切换的开销
1. 什么是“昂贵”的上下文切换?
首先,我们要明确,为什么切换线程很贵?
当 CPU 从 线程 A 切换到 线程 B 时,不仅仅是“换个人干活”这么简单,它涉及两个巨大的成本:
-
直接成本 (CPU 寄存器重置):
-
CPU 需要把线程 A 的“现场”(程序计数器 PC、堆栈指针 SP、通用寄存器等)保存到内存里。
-
然后从内存里把线程 B 的“现场”恢复到寄存器里。
-
这本身需要花费几微秒 ($\mu s$)。
-
-
间接成本 (Cache 失效 —— 这才是真正的杀手):
-
CPU 有 L1/L2/L3 高速缓存。线程 A 跑得正欢的时候,缓存Cache里全是线程 A 需要的数据(热数据)。
-
突然切到线程 B,线程 B 要用的数据不在缓存里(Cache Miss)。
-
CPU 被迫去慢如蜗牛的内存(RAM)里拿数据。
-
这会导致 CPU 的执行效率瞬间暴跌。
-
2. 多线程模式的痛点 (The “Context Switch Storm”)
假设 Redis 是传统的多线程模型(比如像早期的 Tomcat 或 MySQL):
-
场景: 来了 1000 个请求。
-
处理: 系统开启 1000 个线程(或者用线程池)。
-
锁竞争: 线程 A 要修改 Key “user:1”,线程 B 也要修改。线程 B 抢不到锁,被迫挂起 (Block)。
-
自愿切换 (Voluntary Context Switch):
-
因为抢不到锁,或者等待磁盘 I/O,线程 B 主动告诉操作系统:“我干不下去了,把 CPU 让给别人吧。”
-
操作系统进行上下文切换。
-
-
结果: 在高并发下,CPU 把大量的时间花在** “保存现场、恢复现场、调度线程、等待锁” **上,真正用来执行
set name gemini这行代码的时间反而被挤压了。
3. Redis 的单线程魔法 (The “Run-to-Completion”)
Redis 的主处理逻辑(Command Execution)是单线程的,这意味着:
A. 彻底消灭“锁竞争”
-
因为只有我一个人(主线程)在动数据,所以我根本不需要锁(Lock-free)。
-
没有锁,就不会出现“因为抢不到锁而挂起”的情况。
-
不存在“挂起”,就没有“自愿上下文切换”。
-
结果: Redis 主线程是一路狂奔的,它处理完一个请求,马上处理下一个,中间没有任何停顿。
B. 极致的 Cache 亲和性 (Cache Affinity)
-
因为始终是这同一个线程在这一颗 CPU 核心上跑。
-
Redis 的核心数据结构(dict, ziplist, skiplist)和代码指令,会一直停留在 CPU 的 L1/L2 缓存里。
-
Cache Hit 率极高。
-
这就像一个熟练工人在自己的工位上干活,所有工具都在手边(L1 Cache),闭着眼睛都能拿到。
C. I/O 多路复用 (Epoll) —— 避免 I/O 阻塞
-
你可能会问:“那如果读 Socket 数据的时候,数据还没来怎么办?线程不就阻塞了吗?”
-
Redis 使用 epoll (Linux)。
-
机制: Redis 告诉内核:“这一万个 Socket 你帮我盯着,谁有数据来了你告诉我。”
-
非阻塞: Redis 主线程永远不会在某个 Socket 上死等(Block)。它只处理那些“已经准备好数据”的 Socket。
-
所以,Redis 永远不会因为 I/O 等待而发生上下文切换。
4. 总结对比:多线程 vs 单线程
我们可以用去银行办事来比喻:
| 模式 | 场景比喻 | 上下文切换情况 | 效率 |
|---|---|---|---|
| 多线程模型 | 10 个窗口,10 个柜员。 所有的柜员都要抢同一个账本(锁)来记账。抢不到的柜员就去喝茶(切换)。柜员之间换班还要交接工作(保存现场)。 |
极高 (锁竞争、线程调度) |
低 (大量时间花在抢锁和交接上) |
| Redis 单线程 | 1 个超级柜员 (Flash)。 只有他一个人,账本就在手边(Cache)。他动作极快,处理完张三马上处理李四,不用跟任何人抢账本,也不用交接班。 |
极低 (几乎为 0,除非时间片用完) |
极高 (CPU 100% 用在干活上) |
5. 什么时候 Redis 还是会切换?
虽然 Redis 尽力避免切换,但被动切换 (Involuntary Context Switch) 是无法避免的,因为操作系统才是老大。
- 时间片用完 (Time Slice): 操作系统采用了分时调度。给 Redis 的 10ms 用完了,不管你活干没干完,OS 必须强行把 CPU 抢走给别的进程(比如 SSH、系统日志)用一下。
Redis 单线程避免上下文切换的核心在于:它通过“非阻塞 I/O”和“单线程串行执行”,消灭了代码层面的“锁”和“等待”,从而让 CPU 始终处于全速运算的高效状态。
Redis写数据全生命周期
假设有一个 Java 客户端,发送了一条命令 SET user:1 "Alice"。
第一阶段:请求到达与分发 (进 - I/O 阶段)
-
客户端发送:
-
外部的 Java 客户端(用户级线程)发起 TCP 连接,将命令
SET user:1 "Alice"转换成 Redis 协议(RESP),通过网线发送出去。 -
数据到达 Redis 服务器的网卡,进入操作系统的内核 Socket 缓冲区。
-
-
主线程感知 (epoll):
- Redis 的主线程正在运行事件循环(Event Loop),通过
epoll_wait监听到这个 Socket 有数据来了(可读事件)。
- Redis 的主线程正在运行事件循环(Event Loop),通过
-
任务分发 (Distribute):
-
关键点:主线程不亲自去读数据。
-
主线程把这个 Socket 连接分配给一组 I/O 线程(IO Thread Pool) 中的某一个。
-
-
I/O 线程并行读取与解析:
-
多线程并行:被选中的 I/O 线程(内核级线程)发起系统调用
read(),从内核缓冲区把数据搬运到用户态。 -
协议解析:I/O 线程解析数据流,识别出这是一条
SET命令,参数是user:1和Alice。 -
注意:此时主线程会短暂等待,直到所有分配出去的 I/O 任务都完成读取和解析。
-
第二阶段:命令执行 (做 - 执行阶段)
-
主线程串行执行 (Execute):
-
所有 I/O 线程都解析完后,汇报给主线程。
-
单线程独占:主线程按照队列顺序,串行地拿到解析好的命令。
-
内存操作:主线程在内存的
HashMap中找到user:1这个槽位,填入"Alice"。 -
原子性:因为只有主线程在动这个 Map,所以绝对安全,不需要加锁。
-
-
生成结果:
-
执行成功,主线程生成响应结果
+OK。 -
主线程把这个结果写入到该客户端的用户态输出缓冲区中。
-
第三阶段:响应返回 (出 - I/O 阶段)
-
任务再次分发:
-
主线程依然不亲自把数据发回网卡。
-
它再次把“写回数据”的任务分配给 I/O 线程。
-
-
I/O 线程并行回写:
-
I/O 线程并行地调用
write()系统调用,把缓冲区里的+OK发送给内核 Socket 缓冲区。 -
内核负责通过网卡把数据发回给 Java 客户端。
-
第四阶段:持久化 (存 - 后台阶段)
这部分是异步发生的,不影响给客户端返回结果的速度。
-
触发持久化:
-
AOF:主线程刚才执行完
SET后,顺手把这条命令写到了内核缓冲区(Page Cache)。- 后台线程 (BIO):稍后(如每秒)醒来,调用
fsync把内核缓冲区的数据刷到物理磁盘。
- 后台线程 (BIO):稍后(如每秒)醒来,调用
-
RDB:如果满足了触发条件(如 1 分钟改了 1 万次)。
-
主线程:调用
fork生成子进程。 -
子进程:默默地在后台把内存里的
user:1等所有数据写成 RDB 文件。
-
-
Kafka为什么比RocketMQ快
参照物:传统 I/O (Standard I/O)
假设你要把磁盘上的一个文件通过网卡发给消费者(比如读取日志发送)。
代码通常是:read(file, buffer) -> write(socket, buffer)。
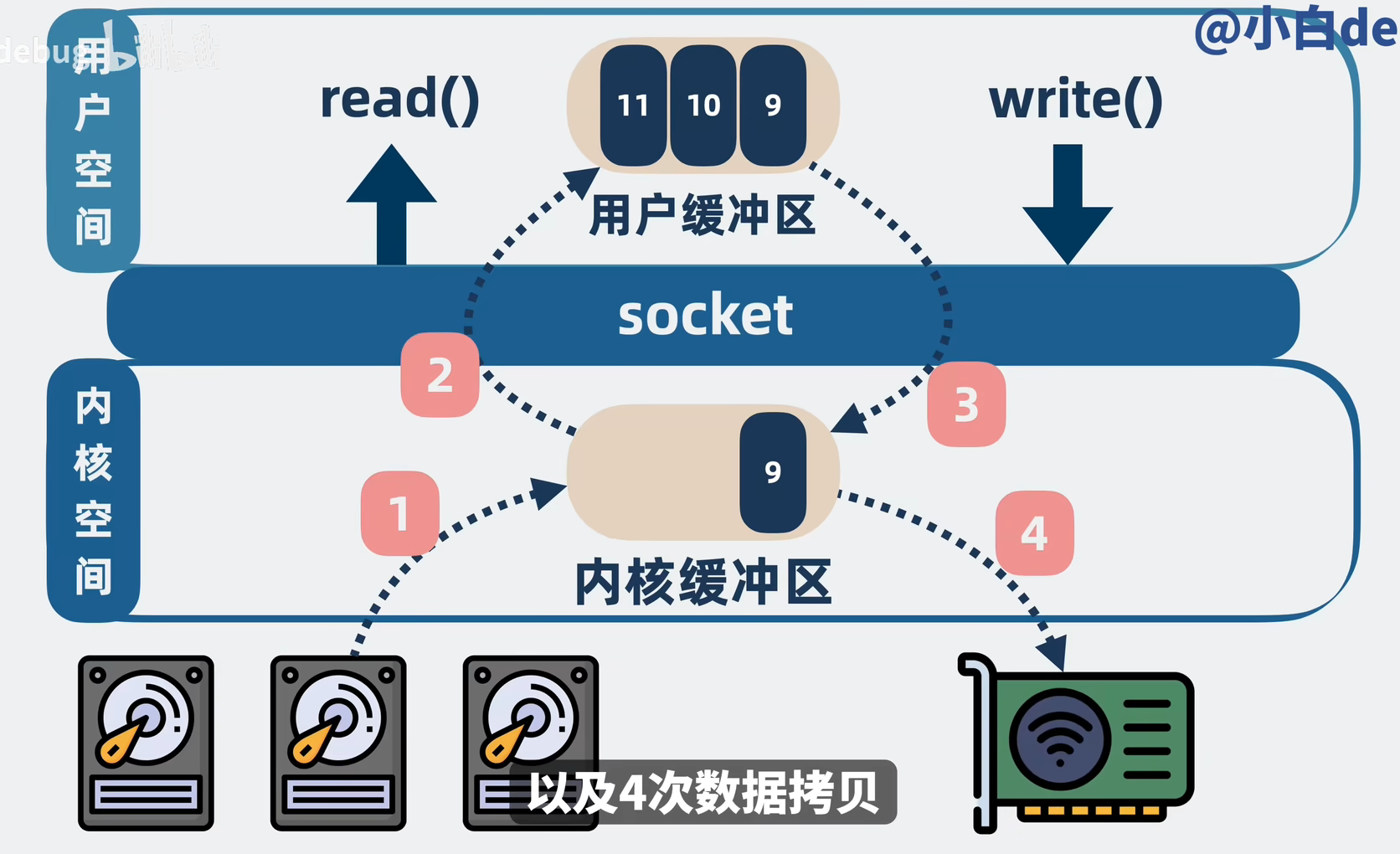
这中间发生了 4 次拷贝 + 4 次上下文切换:
-
DMA 拷贝:磁盘 -> 内核缓冲区(Read Buffer)。
-
CPU 拷贝:内核缓冲区 -> 用户态缓冲区(数据进来了)。
-
CPU 拷贝:用户态缓冲区 -> 内核 Socket 缓冲区(数据又出去了)。
-
DMA 拷贝:Socket 缓冲区 -> 网卡。
痛点:数据在内核和用户态之间反复横跳,CPU 忙着搬运数据,没空干别的。
Kafka 的绝技:sendfile (数据管道)
Kafka 在发送消息给消费者时,调用了 Java 的 FileChannel.transferTo(),底层就是 Linux 的 sendfile 系统调用。
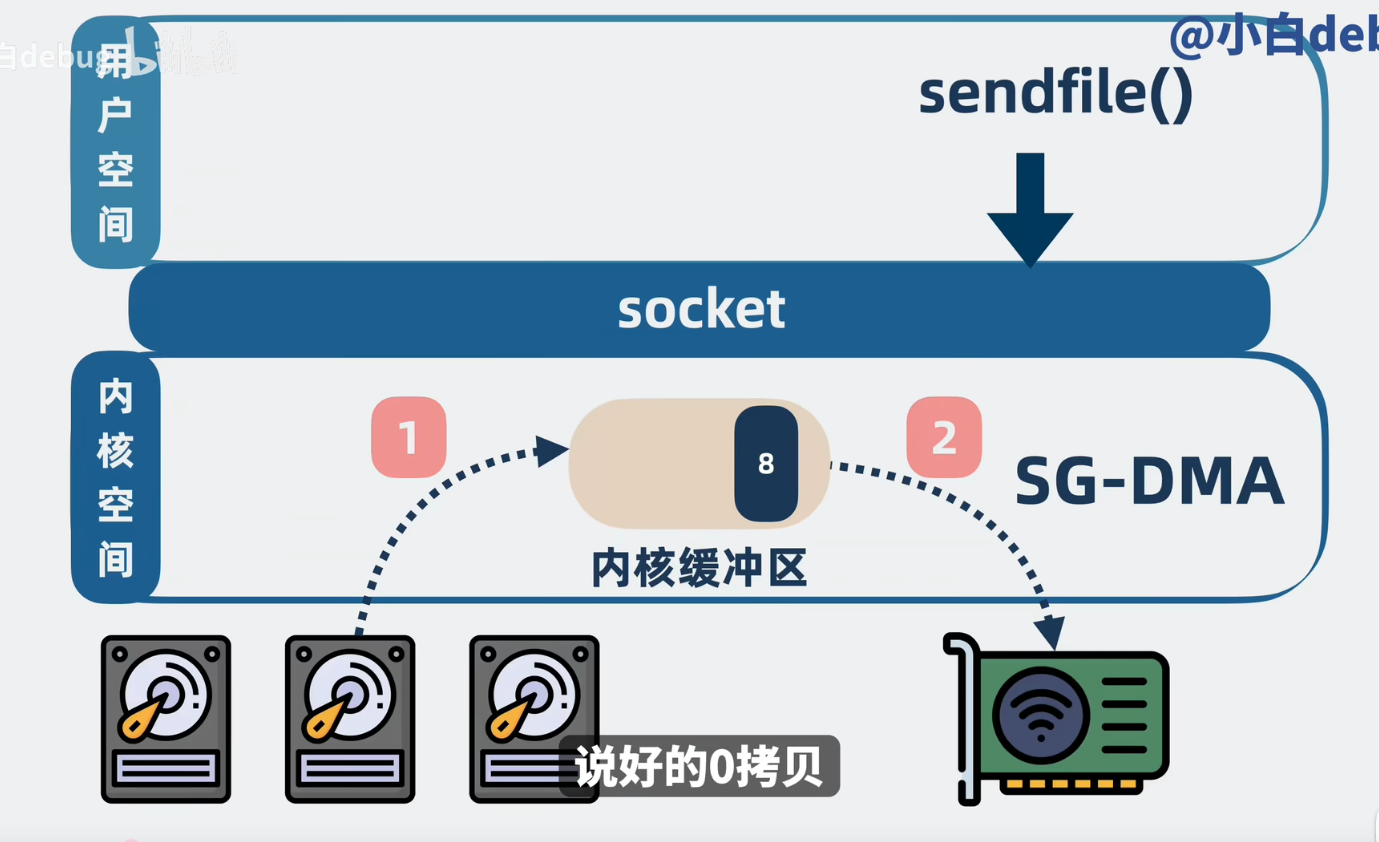
核心机制
sendfile 告诉内核:“把这个文件里的数据,直接发给那个 Socket,不要经过我的手(用户态)。”
流程(2 次拷贝 + 2 次切换):
-
DMA 拷贝:磁盘 -> 内核缓冲区 (Page Cache)。
-
CPU/DMA 拷贝:
-
早期 Linux:内核缓冲区 -> Socket 缓冲区。
-
现代 Linux (DMA Gather Copy):内核缓冲区 -> 直接给网卡(只把描述符给 Socket,真正做到了 CPU 0 拷贝)。
-
这里的零拷贝指的是零CPU拷贝。
RocketMQ 的绝技:mmap (内存映射)
RocketMQ 选择了 mmap(Memory Mapped Files),在 Java 中对应 MappedByteBuffer。
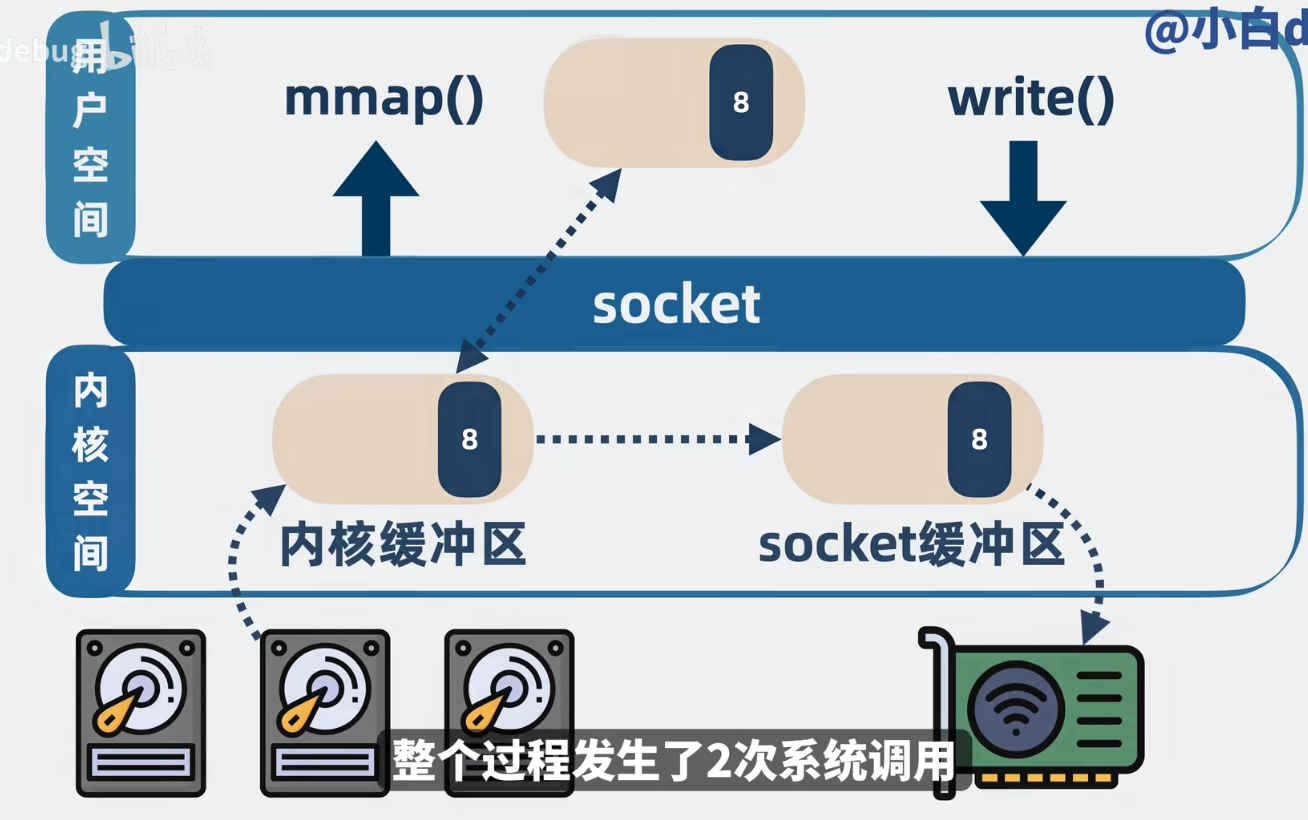
核心机制
mmap 告诉内核:“把磁盘上的这个文件,映射到我的虚拟内存地址里来。”
流程:
-
建立映射:用户态的一个虚拟地址指针,直接指向内核的 Page Cache。
-
读写数据:
-
RocketMQ 读取这个指针,就像读内存数组一样简单。
-
操作系统负责在后台利用 DMA 把磁盘数据加载到 Page Cache(缺页中断机制)。
-
-
发送数据:RocketMQ 读取这块“内存”,然后 write 给 Socket。
- 这里依然需要一次 CPU 拷贝(从映射内存拷贝到 Socket 缓冲区)。
| 特性 | Kafka (sendfile) | RocketMQ (mmap) |
|---|---|---|
| 数据路径 | 磁盘 -> 内核 -> 网卡 | 磁盘 -> 内核 -> 用户态 -> 内核 -> 网卡 |
| CPU 参与度 | 极低 (几乎不参与拷贝) | 中等 (需要一次 CPU 拷贝) |
| 用户态可见性 | 不可见 (黑盒传输) | 可见 (可读、可修改) |
| 适用场景 | 海量数据流式传输 (只管发,不处理) | 复杂业务消息 (需要过滤 Tag、事务回查等) |
| Java API | FileChannel.transferTo() |
MappedByteBuffer |
| 限制 | 无法对内容进行逻辑处理 | 文件不能太大 (RocketMQ 限制 1GB) |
Kafka 之所以吞吐量宇宙第一,是因为它放弃了对消息细节的掌控,直接用 sendfile 当了一个“甩手掌柜”,把数据直接丢给网卡。
RocketMQ 之所以功能强大(支持 Tag 过滤、复杂的事务状态),是因为它用了 mmap,保留了对数据的访问权,虽然牺牲了一点点传输性能,但换来了业务灵活性。
一句话概括:Kafka 是为了“运货”而生,RocketMQ 是为了“验货”而生。
Page Cache 是 Linux 内核为了掩盖磁盘龟速而用闲置内存做的“障眼法”。
为什么RPC/HTTP2能比HTTP1.1快那么多
简单来说,HTTP/1.1 像是单车道,而 HTTP/2 + RPC 像是多车道高速公路,且路上跑的都是压缩后的跑车而不是臃肿的大卡车。
以下是具体的技术核心差异:
1. 多路复用 (Multiplexing) —— 解决核心痛点
这是 HTTP/2 相比 HTTP/1.1 最大的性能提升点,解决了“队头阻塞”(Head-of-Line Blocking)问题。
-
HTTP/1.1 的问题:
在同一个 TCP 连接中,请求是串行的。浏览器/客户端必须等上一个请求响应回来,才能发下一个。如果第一个请求处理很慢(比如数据库卡了),后面的所有请求都会被堵住。
- 补救措施: 浏览器通常会针对同一个域名建立 6 个 TCP 连接来并行传输,但这对服务器资源消耗很大。
-
HTTP/2 (RPC) 的方案:
它引入了 流 (Stream) 和 帧 (Frame) 的概念。
-
所有的请求和响应都共用同一个 TCP 连接。
-
不同的请求被拆分成许多小的二进制“帧”,这些帧像洗牌一样混在一起传输,每一帧都有 ID 标识属于哪个请求。
-
结果: 请求 A 的数据包不需要等请求 B 处理完就能发送。高并发下,吞吐量极高。
-
2. 头部压缩 (HPACK) —— 节省带宽
在微服务架构中,RPC 调用非常频繁,HTTP 头部(Headers)占用的开销比你想象的要大。
-
HTTP/1.1 的问题:
HTTP 是无状态的,每次请求都会携带完整的 Header(如 User-Agent, Cookie, Accept 等)。这些全是纯文本,往往几百字节甚至上 KB。如果你的请求体(Body)只有几十字节,那传输的有效数据比例极低。
-
HTTP/2 (RPC) 的方案:
使用了 HPACK 算法。
-
客户端和服务器共同维护一张动态表和静态表。
-
如果发送过
User-Agent: Chrome,第二次只需要发送一个索引号(比如1),服务器查表就知道是User-Agent: Chrome。 -
这使得 Header 的大小几乎可以忽略不计。
-
3. 二进制分帧 (Binary Framing) —— 解析更快
计算机处理二进制数据远快于处理文本。
-
HTTP/1.1 的问题:
是文本协议。解析文本需要处理换行符、空格、大小写等,对于高并发服务器来说,解析 JSON 或 HTTP 报文会消耗大量的 CPU 资源。
-
HTTP/2 (RPC) 的方案:
是二进制协议。数据在传输层就已经被分割为更小的消息和帧,并采用二进制编码。机器解析起来非常高效,出错率低,且更紧凑。
4. 序列化协议 (Serialization) —— RPC 的独门秘籍
这一条主要针对 RPC(如 gRPC 使用的 Protocol Buffers)对比传统的 RESTful (HTTP/1.1 + JSON)。
-
HTTP/1.1 + JSON:
JSON 是基于文本的,冗余度极高。比如 {“id”: 12345, “name”: “user”},你需要传输字段名 id 和 name。且 JSON 的解析(反序列化)非常耗 CPU。
-
RPC (Protobuf):
使用 Protocol Buffers (Protobuf) 或 Thrift 等二进制序列化协议。
-
体积小: 它是通过 ID 映射字段,不传输字段名,压缩后的体积通常只有 JSON 的 1/3 到 1/10。
-
速度快: 二进制流直接映射到内存对象,序列化/反序列化速度比 JSON 快 5-10 倍。
-
5. 服务端推送 (Server Push)
虽然在 RPC 场景下用得相对少,但 HTTP/2 允许服务器在客户端请求之前“主动”推送资源,减少了往返延迟(RTT)。
总结对比
| 特性 | HTTP/1.1 | HTTP/2 (及 gRPC) | 优势 |
|---|---|---|---|
| 传输格式 | 文本 (Text) | 二进制 (Binary) | 解析更快,体积更小 |
| 连接模型 | 串行 (Keep-Alive) | 多路复用 (Multiplexing) | 解决队头阻塞,极大提高并发 |
| 头部开销 | 巨大 (纯文本重复发送) | HPACK 压缩 | 节省带宽 |
| 负载内容 | 通常是 JSON (大、慢) | 通常是 Protobuf (小、快) | 序列化性能提升明显 |
| TCP 连接数 | 多个 (通常 6 个) | 只需 1 个 | 降低服务器握手和资源开销 |
HeavyKeeper和LRU,LFU
可以将它们的关系理解为:LRU 和 LFU 是“怎么扔垃圾”,而 HeavyKeeper 是“怎么用极小的代价找出谁是大佬”。
以下是详细的对比和原理解析:
1. LRU (Least Recently Used) - 最近最少使用
核心逻辑: “如果数据最近被访问过,那么它将来被访问的几率也很大。”
-
关注点: 时间(Recency)。
-
工作原理:
-
新数据或刚被访问的数据放到队头。
-
缓存满时,直接淘汰队尾的数据(最久没被摸过的)。
-
-
优点:
-
实现简单(HashMap + 双向链表)。
-
适应突发性流量(Burst Traffic),因为热点往往是临近的。
-
-
缺点:
- 缓存污染(Cache Pollution): 如果进行一次全表扫描(读取大量数据但只用一次),会把原本的热点数据全部挤出缓存,导致缓存命中率急剧下降。
2. LFU (Least Frequently Used) - 最不经常使用
核心逻辑: “如果数据过去被访问多次,那么它将来被访问的几率也很大。”
-
关注点: 频率(Frequency)。
-
工作原理:
-
为每个数据维护一个计数器。
-
缓存满时,淘汰计数器数值最小的数据。
-
-
优点:
-
抗扫描能力强。偶尔的一次性批量读取不会挤掉长期积累的热点数据。
-
对于长期稳定的热点数据,命中率极高。
-
-
缺点:
-
实现复杂且内存开销大: 需要维护所有数据的计数器,且排序复杂度较高。
-
旧数据滞留(Dusty Cache): 一个以前很热但现在没用的数据(比如上个月的爆款商品),因为计数器很高,会一直霸占缓存,如果不引入衰减机制,很难被淘汰。
-
3. HeavyKeeper - 专门抓“大象”的守门员
核心逻辑: “我不追求 100% 精确,但我用极小的内存就能告诉你谁是真正的热点(Top-K)。”
-
关注点: 极低内存下的频率预估。
-
本质: 它不是一个完整的缓存系统,而是一个算法结构(通常基于 Count-Min Sketch 的改进)。它常被用于 Redis 的热点发现工具或现代缓存系统(如 Caffeine 库)的频率过滤器中。
-
工作原理(指纹衰减):
-
它使用类似哈希表的结构,但存储的是指纹(Fingerprint)和计数。
-
关键创新: 传统的 Sketch 算法在哈希冲突时会错误地增加计数(导致高估)。HeavyKeeper 引入了衰减机制——当新元素进入并发生哈希冲突时,如果指纹不匹配,它会以一定概率减少(Decay)原有的计数器。
-
结果: “小鼠流”(低频数据)的计数会被不断衰减消灭,“大象流”(高频数据)因为访问足够多,能抵抗衰减并幸存下来。
-
-
优点:
-
内存占用极小: 相比 LFU 记录所有 key 的完整计数,HeavyKeeper 只需要很少的 bucket 就能大概率找准热点。
-
误差可控: 专门为 Top-K 场景设计,对高频数据极其准确。
-
总结对比表
| 特性 | LRU (时间) | LFU (频率) | HeavyKeeper (概率频率) |
|---|---|---|---|
| 全称 | Least Recently Used | Least Frequently Used | HeavyKeeper |
| 核心维度 | 最近访问时间 | 访问总次数 | 访问总次数 (概率性) |
| 主要用途 | 缓存淘汰策略 | 缓存淘汰策略 | 热点检测 (Top-K) / 辅助 LFU |
| 抗扫描能力 | 弱 (容易被冲刷) | 强 | 强 |
| 空间开销 | 中 (存 Key + 链表指针) | 大 (存 Key + 计数器) | 极小 (哈希桶 + 指纹) |
| 实现复杂度 | 低 ($O(1)$) | 高 (需堆或多级链表) | 中 (哈希 + 概率逻辑) |
| 精准度 | 精确 | 精确 | 有误差 (但对热点准确) |
| 典型应用 | MySQL Buffer Pool (改进版), 操作系统页置换 | 传统缓存系统 | Redis 热 key 发现, 网络流量分析 |
LRU代码实现
|
|
Redis的大key的问题怎么解决
由于 Redis 是单线程模型,处理一个巨大的 Key(无论是读取、写入还是删除)都会占用主线程,导致后续请求排队等待,造成 “卡顿”。
以下是系统化的解决思路,分为 发现、删除 和 治理(预防) 三个阶段。
一、 什么是 Big Key?(标准定义)
通常根据 Value 的大小或元素数量来判定:
-
String 类型: Value > 10KB(严格标准)或 1MB(宽松标准)。
-
集合类型(Hash, List, Set, ZSet): 元素个数 > 5000 或 10000 个。
二、 如何发现 Big Key?
在治理之前,首先要定位它们。
-
redis-cli --bigkeys命令:-
Redis 自带的工具,会扫描整个 Key 空间。
-
缺点: 它是阻塞式的扫描(虽然用了 SCAN),在数据量巨大时可能会轻微影响性能,且只能返回每种类型最大的那个 Key,信息不全。
-
-
MEMORY USAGE key命令:- 如果你怀疑某个 Key 是大 Key,可以用这个命令查询其实际内存占用。
-
RDB 文件分析(推荐):
-
使用工具(如
rdb-tools或redis-rdb-tools)离线分析 RDB 备份文件。 -
优点: 完全不影响线上 Redis 性能,生成的报告非常详细(包含 Key 名称、大小、类型)。
-
-
监控告警:
-
如果在云服务商(如阿里云、AWS)上,通常控制台会有 “大 Key 分析” 功能。
-
监控网络带宽,如果网络流出流量瞬间飙升,通常是有客户端读取了大 Key。
-
三、 如何安全地删除 Big Key?
绝对禁止直接使用 DEL 命令删除大 Key!
DEL 是同步阻塞操作,删除一个几百 MB 的 Key 可能会阻塞 Redis 几秒钟,导致故障转移或请求超时。
1. Redis 4.0 及以上版本(推荐)
使用 UNLINK 命令代替 DEL。
- 原理:
UNLINK只是将 Key 从元数据中解绑(逻辑删除),真正的内存回收操作会由后台线程(Lazy Free)异步执行,不会阻塞主线程。
2. Redis 4.0 以下版本(手动渐进式删除)
如果版本较老,必须手动分批删除,避免阻塞:
-
Hash: 使用
HSCAN每次扫描一部分字段,然后用HDEL删除。 -
List: 使用
LPOP/RPOP或LTRIM分批删除。 -
Set: 使用
SSCAN扫描,SREM删除。 -
ZSet: 使用
ZREMRANGEBYRANK分批删除。
四、 如何彻底解决(设计与预防)?
删除只是治标,只有修改业务设计才能治本。
1. 拆分(Split)
将一个大 Key 拆分为多个小 Key。
-
场景: 一个 Hash 存储了 100 万个用户对象。
-
方案: 使用 Hash 取模设计。例如定义
hash_0到hash_99共100个 Bucket。-
存取时:
id % 100决定存入哪个 Key。 -
这样每个 Key 的大小就只有原来的 1/100。
-
2. 压缩(Compression)
对于 String 类型的长文本(如 JSON、XML),使用压缩算法。
- 方案: 写入 Redis 前使用 Gzip、Snappy 或 Protobuf 进行压缩/序列化。通常能减少 50%-80% 的体积。
3. 剪裁与清洗(Pruning)
不要把 Redis 当数据库用,只存 “热点数据”。
-
场景: 一个 List 存了用户的历史浏览记录,长达几万条。
-
方案: 业务上只需要展示最近 100 条。在写入时维持定长队列(
LTRIM),或者定期清理过期数据。
4. 设置过期时间(TTL)
- 防止 “僵尸” 大 Key 长期占用内存。给 Key 设置合理的 TTL,让其自动过期删除(注意:Redis 的自动过期在 4.0 之前删除大 Key 也可能阻塞,4.0+ 配置
lazyfree-lazy-expire yes可解)。
5. 存储转移(Offloading)
-
如果数据本身就是很大(例如图片二进制、长文章),且必须完整读取,那么它不适合存入 Redis。
-
方案: 存入 S3、MongoDB 或 CDN,Redis 只存该数据的 URL 或索引 ID。
总结对照表
| 策略 | 适用场景 | 关键手段 |
|---|---|---|
| 发现 | 线上排查 / 离线分析 | redis-cli --bigkeys, RDB Tools |
| 应急处理 | 此时此刻必须删除 | UNLINK (异步删除) |
| 架构优化 | 集合元素过多 | 拆分 (Sharding/Bucketing) |
| 架构优化 | 文本 Value 过大 | 压缩 (Gzip/Snappy) |
| 架构优化 | 无效数据堆积 | 定期清理 (LTRIM) / 设置 TTL |
Redis是怎么找到key存储在哪个节点上?
Redis 在集群模式(Redis Cluster)下,并不是直接把 Key 存到节点上的,而是引入了一个中间层:哈希槽 (Hash Slot)。
简单来说,Redis 集群预分好了一万多个坑位(Slot),所有的 Key 都要先算一下自己该去哪个坑,而具体的节点(Node)只是负责管理这些坑位。
以下是具体的寻址过程,分为 理论计算 和 客户端交互 两个层面。
一、 核心算法:CRC16 + 取模
Redis Cluster 固定的将数据空间划分为 16384 个哈希槽(编号 0 ~ 16383)。
当你要存储一个 Key(比如 set name lucius)时,Redis 会通过以下两步计算出这个 Key 属于哪个槽:
-
计算哈希值:使用 CRC16 算法对 Key 进行计算,得到一个整数。
-
取模运算:将得到的整数对 16384 取模。
公式:
$$ Slot = CRC16(key) \pmod{16384} $$计算出 Slot 编号(比如 5000)后,Redis 只需要查看当前集群配置中,编号 5000 的槽是由哪个节点负责的,就能确定数据在哪个节点。
二、 生动比喻:快递分拣中心
为了方便理解,我们可以把 Redis Cluster 想象成一个巨大的物流分拣系统:
-
货物 (Key):你要存的数据。
-
快递筐 (Hash Slot):系统里一共有 16384 个固定的筐子,编号 0-16383。
-
货车 (Node):实际负责运货的物理服务器(比如有 3 台服务器 A、B、C)。
流程是这样的:
-
分配规则:
-
货车 A 负责运送 0 ~ 5500 号筐子。
-
货车 B 负责运送 5501 ~ 11000 号筐子。
-
货车 C 负责运送 11001 ~ 16383 号筐子。
-
-
存货过程:
-
来了一个包裹
name。 -
系统算一下(CRC16),发现它应该进 5000 号筐子。
-
查表发现 5000 号筐子归 货车 A 管。
-
于是包裹被丢进货车 A。
-
为什么要这么设计?
如果因为业务繁忙,你要加一辆货车 D,你不需要把所有包裹重新拆包计算一遍。你只需要把 货车 A 上的一部分筐子(比如 0~1000号)搬到 货车 D 上即可。
这就是 Redis Cluster 扩容方便的原因:数据迁移的单位是“槽”,而不是单个 Key。
三、 客户端是怎么知道去哪个节点的?
虽然服务器知道槽位映射关系,但**客户端(比如你的 Java 代码)**是怎么知道的呢?
通常有两种情况:
1. 笨客户端(每次都问,或问错了)—— MOVED 重定向错误
假设客户端不知道 Key name 在哪个节点,它随便连了一个节点(比如节点 B)发送命令:GET name。
-
节点 B 收到命令,计算
CRC16('name') % 16384,发现属于 Slot 5000。 -
节点 B 查自己的小本本,发现 Slot 5000 归 节点 A 管。
-
节点 B 不会帮客户端去取数据(因为那是代理做的事),而是直接返回一个错误:
MOVED 5000 192.168.1.100:6379
(翻译:哥们你找错人了,这个 Key 归 5000 号槽管,那个槽在 IP 为 … 的节点上,你自己去找它吧。)
-
客户端收到报错,根据新地址,重新去连接节点 A。
2. 聪明客户端(Smart Client,如 Jedis, Lettuce)—— 本地缓存
为了性能,现在的客户端(如 Java 的 Jedis、Lettuce)在启动时,会先连接集群,把 Slot -> Node 的映射表 下载下来缓存在本地内存里。
-
你要
GET name。 -
Java 客户端在本地算一下:Slot = 5000。
-
查本地缓存:Slot 5000 -> 节点 A。
-
直接连接节点 A 发送请求。
这避免了额外的网络跳转,效率最高。
四、 特殊情况:Hash Tag(强制特定 Key 去特定节点)
面试高频考点:
由于 CRC16 算法是随机的,user:1001 和 order:1001 很大概率会被分到不同的节点上。
这就导致一个问题:如果你想在一个事务(Multi/Exec)里同时操作这两个 Key,或者用 Lua 脚本同时处理它们,会报错! 因为 Redis 要求事务或脚本涉及的所有 Key 必须在同一个节点上。
解决方案:Hash Tag {}
你可以在 Key 中使用花括号 {}。Redis 计算 Hash 时,如果发现 Key 里有 {},就只计算 {} 内部字符串的 Hash 值。
-
Key 1:
user:{1001}-> 计算CRC16("1001") -
Key 2:
order:{1001}-> 计算CRC16("1001")
因为 {} 里的内容一样,算出来的 Slot 肯定一样,它们就一定会落到同一个节点上。
没有 Hash Tag 之前,Redis 的分拣员(CRC16 算法)是非常老实的,它会把 Key 的每一个字符都算进去。
1. 没有 Hash Tag(老实模式)
分拣员看到什么就算什么,全名参与计算。
-
Key A:
user:1001-
算法输入:
"user:1001"(9 个字符) -
结果:哈希值 X $\rightarrow$ 对应 Slot 500
-
-
Key B:
order:1001-
算法输入:
"order:1001"(10 个字符) -
结果:哈希值 Y $\rightarrow$ 对应 Slot 8000
-
因为 "user:1001" 和 "order:1001" 是完全不同的两个字符串,算出来的结果自然千差万别,所以它们被分到了不同的节点。
2. 有 Hash Tag(偷懒模式)
分拣员一旦看到 {},就只算花括号里面的内容,外面的前缀后缀全当看不见。
-
Key A:
user:{1001}-
算法输入:
"1001"(只算这 4 个数字) -
结果:哈希值 Z $\rightarrow$ 对应 Slot 300
-
-
Key B:
order:{1001}-
算法输入:
"1001"(还是只算这 4 个数字) -
结果:哈希值 Z $\rightarrow$ 对应 Slot 300
-
因为输入完全一样(都是 "1001"),所以算出来的 Slot 编号绝对一样,这两个 Key 就必定会去同一个节点“团聚”。
小贴士(Hash Tag使用风险)
虽然 Hash Tag 很好用,但千万不要滥用。
如果你把几百万个 Key 都加上同一个 Hash Tag(比如 user:{beijing}),那么这几百万个 Key 算出来的 Slot 全都一样,它们会全部挤到同一台机器上。
后果: 这就导致了数据倾斜(Data Skew)—— 集群里的一台机器忙死(内存爆满、CPU 飙升),而其他机器闲死。
MySQL三层B+树能存储多少数据?
但在通常的估算标准下(主键为 BigInt,单行数据约 1KB),三层 B+ 树大约能存储 2000 万(2000w)条数据。
1. 核心预设条件
MySQL 的 InnoDB 存储引擎有以下几个默认属性,这是计算的基础:
-
页大小 (Page Size):默认是 16KB ($16384$ 字节)。
-
指针大小:InnoDB 页指针为 6 字节。
-
主键类型:通常假设为
BigInt(8 字节)。如果用Int(4 字节),存的更多。
2. B+ 树结构拆解
B+ 树分为非叶子节点(存索引和指针)和叶子节点(存真实数据)。
第一步:计算非叶子节点能存多少索引?
非叶子节点不存数据,只存“主键 + 指针”。
-
单个索引项大小 = 主键大小 (8B) + 指针大小 (6B) = 14 字节。
-
单页可存索引数 = 页大小 / 索引项大小 = $16384 / 14 \approx 1170$ 个。
这意味着,一个非叶子节点可以指向 1170 个下级节点。
第二步:计算叶子节点能存多少数据?
叶子节点存储真实的行数据。这里变量最大的就是“一行数据的大小”。
-
假设 1:一行数据大小为 1KB(比较常见的预设)。
-
单页可存行数 = $16384 / 1024 = 16$ 条。
3. 三层 B+ 树容量计算
结构如下:
-
根节点(第1层):非叶子节点,指向 1170 个第2层节点。
-
分支节点(第2层):非叶子节点,每个节点指向 1170 个叶子节点。总共有 $1170 \times 1170$ 个叶子节点。
-
叶子节点(第3层):存数据。
计算公式:
$\text{总记录数} = (\text{根节点指针数}) \times (\text{第二层指针数}) \times (\text{叶子节点单页行数})$
代入数值(行数据 1KB):
$1170 \times 1170 \times 16 \approx \mathbf{21,902,400}$
结论 1: 如果一行数据是 1KB,三层能存约 2190 万 条数据。
4. 如果数据行很小怎么办?
有些表可能只有几个字段,一行数据可能只有 100 字节。如果不算页分裂等损耗:
-
单页可存行数 = $16384 / 100 \approx 160$ 条。
-
总容量 = $1170 \times 1170 \times 160 \approx \mathbf{2.19 亿}$。
结论 2: 数据行越小,三层 B+ 树能存的数据就越多,甚至能过亿。
5. 现实中的误差(Fill Factor)
上面的计算是理论最大值(所有页都填满 100%)。但在实际运行中:
-
页头页尾开销:每个页有 Header、Directory Slot 等元数据,大约占用几十到几百字节,不能全用来存数据。
-
页填充率:InnoDB 不会把页填得满满当当,为了减少页分裂,通常填充率在 1/2 到 15/16 之间。如果频繁随机插入,页碎片化会导致填充率下降。
如果按照 50%-75% 的利用率折算,通常认为三层树的舒适区确实就在 2000万 左右。一旦超过这个数量级,B+ 树可能分裂出第四层,导致磁盘 I/O 增加,查询性能轻微下降。
事务的四大特性(ACID)
为了保证上述逻辑的严密性,数据库理论规定事务必须满足 ACID 四个特性,这经常在面试中被问到:
-
A - 原子性 (Atomicity):
-
核心:要么全做,要么全不做。
-
实现靠 Undo Log(回滚日志)。
-
-
C - 一致性 (Consistency):
- 核心:事务前后,数据必须符合逻辑(比如转账前后,两人的钱加起来总数不变)。
-
I - 隔离性 (Isolation):
-
核心:多个事务并发执行时,互不干扰(这就是我们之前讨论的 RR、RC 隔离级别)。
-
实现靠 锁 + MVCC。
-
-
D - 持久性 (Durability):
-
核心:事务一旦提交,数据就是永久的,哪怕下一秒服务器爆炸,重启后数据依然在。
-
实现靠 Redo Log(重做日志)。
-
MySQL的事务隔离级别
并发事务的三大问题
-
脏读 (Dirty Read):事务 A 读到了事务 B 未提交的数据。如果 B 回滚,A 读到的就是脏数据。
-
不可重复读 (Non-repeatable Read):事务 A 在同一个事务中两次读取同一行数据,结果不一样。这是因为在两次读取之间,事务 B 修改或删除了该数据并提交了。
-
幻读 (Phantom Read):事务 A 在同一个事务中两次查询同一个范围,第二次发现多了一些数据。这是因为在两次查询之间,事务 B 插入了新数据并提交了。
四种隔离级别详解
按照隔离程度从低到高排序:
1. 读未提交 (Read Uncommitted)
-
描述:这是最低的隔离级别。一个事务可以读取到另一个事务未提交的修改。
-
现象:相当于“裸奔”,没有任何隔离。
-
存在问题:脏读、不可重复读、幻读都会发生。
-
应用场景:实际开发中极少使用。
2. 读已提交 (Read Committed - RC)
-
描述:一个事务只能读取到已经提交的数据。
-
实现原理:MVCC(多版本并发控制)。每次执行
SELECT语句时,都会重新生成一个 Read View(一致性视图)。 -
存在问题:解决了“脏读”,但可能发生“不可重复读”(因为每次 Select 都生成新视图,如果中间有人提交修改,你就能看到)。
-
备注:这是大多数主流数据库(如 Oracle, PostgreSQL, SQL Server)的默认隔离级别,但不是 MySQL 的默认值。
3. 可重复读 (Repeatable Read - RR) —— MySQL 默认
-
描述:确保在同一个事务中,多次读取同样的数据结果是一样的。
-
实现原理:MVCC。与 RC 不同的是,RR 级别下,Read View 是在事务启动后的第一次查询时生成的,之后一直复用这个视图。
-
存在问题:解决了“脏读”和“不可重复读”。
-
关于幻读:在标准 SQL 定义中,RR 是无法解决幻读的。但是,MySQL 的 InnoDB 引擎通过 MVCC + Next-Key Lock 技术,在 RR 级别下很大程度上避免了幻读(正如我上一个回答所解释的)。
4. 串行化 (Serializable)
-
描述:最高的隔离级别。它强制事务串行执行,通过强制对读取的数据行加锁(共享锁),避免了并发冲突。
-
存在问题:解决了所有问题(脏读、不可重复读、幻读)。
-
代价:并发性能极差,容易导致大量的超时和锁竞争。
-
应用场景:只有在对数据一致性要求极高且并发量很小的场景下才会使用。
隔离级别对比总结表
| 隔离级别 | 脏读 | 不可重复读 | 幻读 | 性能 | 备注 |
|---|---|---|---|---|---|
| Read Uncommitted | ✅ 可能 | ✅ 可能 | ✅ 可能 | 极高 | 极少使用 |
| Read Committed (RC) | ❌ 无 | ✅ 可能 | ✅ 可能 | 高 | Oracle/PG 默认 |
| Repeatable Read (RR) | ❌ 无 | ❌ 无 | ❌ (大部分解决) | 中 | MySQL 默认 |
| Serializable | ❌ 无 | ❌ 无 | ❌ 无 | 低 | 强制排队,性能差 |
为什么可重复读的情况下不能避免幻读
数据在被修改(Update/Delete)的时候,必须基于“最新”的版本进行,而不能基于“历史”版本。
| 时间点 | 事务 A | 事务 B | 现象/旁白 |
|---|---|---|---|
| 1 | BEGIN; SELECT * FROM users WHERE id = 5; 结果:Empty (空) |
事务 A 确认 id=5 还没人用。 | |
| 2 | BEGIN; INSERT INTO users (id, name) VALUES (5, '小明'); COMMIT; |
事务 B 抢先插入了 id=5 并提交。 | |
| 3 | SELECT * FROM users WHERE id = 5; 结果:Empty (空) |
MVCC 生效。事务 A 依然看不到小明。一切看似正常。 | |
| 4 | UPDATE users SET name = '被修改' WHERE id = 5; 结果:Query OK, 1 row affected |
关键点来了! Update 是“当前读”,它能看到最新的提交。它不仅修改成功了,还把这条记录的“版本号”改成了事务 A 自己的。 |
|
| 5 | SELECT * FROM users WHERE id = 5; 结果:id=5, name=‘被修改’ |
【幻读发生】 事务 A 吓死了:“我刚才查还没有 id=5,怎么我一更新,它就突然冒出来,还被我改了?” |
注意,在第二步的时候,事务2已经插入并且提交了,这个时候数据库的内容发生了变化,后续步骤4进行update的时候就得根据最新的数据进行update,然后更新成功,并且,
假设:
-
事务 A 的 ID = 100。
-
事务 B 的 ID = 200。
幻读示例(自己修改或插入的数据,trx_id会变为自己的,可见)
阶段 1:事务 A 开启,生成 ReadView
-
事务 A 执行第一条 SELECT。
-
生成 ReadView,记录当前活跃事务。此时系统里只有 A。
-
ReadView 只要生成了,在 RR 级别下就永远不会变了。
阶段 2:事务 B 插入并提交
-
事务 B 插入
id=5。 -
这行数据现在的状态是:
{id: 5, name: '小明', trx_id: 200}。 -
事务 B 提交。
阶段 3:事务 A 第一次查询 id=5
-
事务 A 拿着 ReadView 来看这行数据。
-
发现数据的
trx_id是 200。 -
ReadView 判断:200 是在我(100)开启之后才进来的“将来的人”。
-
结论:不可见。
阶段 4:事务 A 执行 UPDATE(关键转折点!)
-
动作:
UPDATE users SET name = '被修改' WHERE id = 5; -
当前读:正如之前所说,UPDATE 也是一种读,但它是“当前读”。它不看 ReadView,直接看物理磁盘。它看到了
trx_id=200的数据(因为 B 已经提交,物理上存在)。 -
修改数据:事务 A 把数据改了。
-
打标签:这是最重要的一步!事务 A 把这行数据的
trx_id更新成了自己的 ID(100)。 -
现在的行数据变成了:
{id: 5, name: '被修改', trx_id: 100}。
阶段 5:事务 A 第二次查询 id=5
-
事务 A 再次执行 SELECT。
-
ReadView 变了吗? 没有,还是那个旧的 ReadView。
-
数据变了吗? 变了。
-
事务 A 再次检查可见性:
-
这行数据的
trx_id是多少? -> 100。 -
当前事务 A 的 ID 是多少? -> 100。
-
触发规则 1:
trx_id等于我自己。 -
结论:可见!
-
你之所以能看到,是因为你通过 UPDATE 操作,把这行数据的所有权**“抢”**过来了。
-
修改前:这行数据属于事务 B(
trx_id=200),对你是“未来数据”,不可见。 -
修改后:这行数据属于事务 A(
trx_id=100),对你是“自家数据”,无条件可见。
ReadView 到底存了什么?
当你第一次执行 SELECT * FROM user 时,生成的 ReadView 是一张黑名单,长这样:
|
|
请注意: 这个列表里完全没有提 user 表或 student 表的名字。它只规定了谁是老数据(可见),谁是活跃数据(不可见)。
这个规则对全库所有表通用。
MVCC简单的流程
事务在第一次select的时候会去检查当前活跃事务,然后会查看下一个要分配的事务id,然后记录下来,后面查询的时候会先去查询当前行数据的trx_id,查看数据的trx_id如果小于当前事务的id就应该直接使用这条数据,如果大于自己的事务id,就去查undo log,顺着undolog版本链找到真正自己能看到的数据,然后修改查询得到的数据。
MySQL的锁
共享锁
在sql语句末尾加上for share代表共享锁,所有事务都可以读,但是不能修改,直至事务提交
|
|
排他锁
在sql语句末尾加上for update代表排他锁,其他事务不能修改,也不能读。
|
|
表锁
-
定义:最基本的锁策略,开销最小。它会锁定整张表。
-
特点:
-
无死锁:因为一次性获取所有需要的锁。
-
并发度低:一个用户在写,其他用户都不能读写。
-
-
适用场景:主要由 MyISAM 引擎使用;InnoDB 在特定情况下(如没有索引或手动指定
LOCK TABLES)也会用到,但通常尽量避免。
意向锁
-
痛点:假设事务 A 锁住了表中的某一行(行锁),此时事务 B 想申请整个表的写锁(表锁)。事务 B 怎么知道表里有没有人正在改数据?它必须遍历每一行去检查,效率极低。
-
定义:意向锁是表级锁。
-
当事务 A 想要给某一行加锁时,必须先给表加一个“意向锁”。
-
这就像在写字楼门口挂个牌子:“楼里有人(意向锁)”。
-
-
作用:事务 B 看到门口有“意向锁”的牌子,就知道表里有人在忙,直接等待,不用进去逐个房间(行)检查了。它主要用于快速判断表锁和行锁的冲突。
行锁
-
定义:InnoDB 的核心特性。只锁定被操作的那一行数据。
-
特点:
-
并发度高:多个人可以同时修改同一张表的不同行。
-
开销大:需要加锁、解锁,且容易发生死锁。
-
-
关键点:InnoDB 的行锁是加在索引上的。如果你查询时没有用到索引,InnoDB 会退化为锁定整张表(虽然实现机制上是把所有行都锁了),导致并发性能大跌。
间隙锁
-
含义:只锁住两个记录之间的**“缝隙”**,不包含记录本身。
-
锁住范围:
(10, 20)—— 指的是大于 10 且小于 20 的范围。 -
作用:纯粹是为了防止插入。别人不能在这个范围内
INSERT任何数据(比如插 15)。但他如果要修改id=20这行数据,Gap Lock 是不管的。
Next-Key Lock
假设数据库表中只有三行数据:id = 10, 20, 30。
-
含义:锁住一段间隙 + 锁住间隙右边的那个记录。
-
锁住范围:
(10, 20]—— 左开右闭区间。 -
组成:即锁住了
(10, 20)这个缝隙,也锁住了20这个记录。 -
作用:既不准你在缝隙里插数据(防幻读),也不准你修改右边那个记录。
$Next\text{-}Key \ Lock = Gap \ Lock + Record \ Lock$
MDL锁
-
定义:它不是用来锁数据的,而是用来锁**表结构(Schema)**的。
-
触发机制(系统自动控制,用户无需显式调用):
-
MDL 读锁:当你对表进行增删改查(DML)时,自动加 MDL 读锁。
-
MDL 写锁:当你对表结构进行修改(DDL,如
ALTER TABLE)时,自动加 MDL 写锁。
-
-
互斥关系:
-
读锁和读锁不互斥(大家可以一起查数据)。
-
读写互斥、写写互斥。这意味着,如果有长事务正在查询数据(持有 MDL 读锁),你此时想给表加个字段(申请 MDL 写锁),会被阻塞。
-
-
危险场景(MDL 风暴):
-
Session A 开启事务查数据(持有 MDL 读)。
-
Session B 想加字段(申请 MDL 写,被阻塞)。
-
Session C 及其后的所有查询(申请 MDL 读),因为写锁优先级通常高于读锁,或者写锁在排队,导致后续所有查询全部堵塞。
-
-
结果:数据库线程瞬间爆满,导致宕机。
索引下推是什么?
MySQL 处理 SQL 语句时,主要分为两层:
-
Server 层(服务器层): 负责解析 SQL、优化器生成执行计划、调用存储引擎接口、并处理最终的数据过滤(
WHERE条件判断)。 -
Storage Engine 层(存储引擎层,如 InnoDB): 负责真正的数据存储、提取,通过索引在磁盘上找数据。
“下推”的意思是: 把原本只能在 Server 层做的事情,推给 存储引擎层去做。
场景复盘
我们使用你的例子:
-
表结构:
user表,有列id(主键),name,age,address等。 -
索引: 联合索引
idx_name_age (name, age)。 -
SQL:
SQL
1SELECT * FROM user WHERE name LIKE '王%' AND age = 20;(注意:这里是
SELECT *,意味着必须回表拿到address等其他字段,不能仅靠覆盖索引)
为什么这个场景特殊?
根据最左前缀原则:
-
name LIKE '王%'是范围查询。索引能帮我们快速定位到所有姓“王”的人的起始位置。 -
但是,一旦使用了范围查询(Range),索引后续的列(这里是
age)就无法用于定位(Seek)了。-
索引里的数据排序是:先按 name 排,name 相同才按 age 排。
-
对于
王五和王六,他们的 age 是无序的(相对于整个“王%”区间),所以引擎必须扫描所有姓王的数据。
-
虽然无法用来定位,但 age 的值确实存在于索引树的叶子节点中。ICP 的核心就在于是否利用了这个已有的数据。
详细对比:无 ICP vs 有 ICP
假设数据库里有 4 条记录,索引结构 (name, age) 如下:
-
(
王五, 10) —— 主键 ID: 1 -
(
王六, 20) —— 主键 ID: 2 <– 目标数据 -
(
王七, 30) —— 主键 ID: 3 -
(
张三, 20) —— 主键 ID: 4
❌ 阶段一:没有 ICP (MySQL 5.6 之前)
在没有 ICP 的时候,存储引擎认为自己的任务就是找所有 name 以“王”开头的数据。它会忽略 age = 20 这个条件,因为按老规矩,范围查询后的列“失效”了。
执行流程:
-
Server 层告诉 InnoDB:“给我找所有
name LIKE '王%'的记录。” -
InnoDB 在索引树上找到第一条
(王五, 10)。-
InnoDB 此时无视
age=10不等于 20 这个事实。 -
InnoDB 拿着 ID: 1 去聚簇索引回表,取出整行数据。
-
InnoDB 把整行数据返回给 Server 层。
-
-
Server 层拿到数据,进行
WHERE判断:age是 20 吗?- 发现是 10,丢弃。
-
InnoDB 继续找下一条
(王六, 20)。- 回表,取整行,返回给 Server。
-
Server 层 判断:
age是 20 吗?- 是,保留。
-
InnoDB 继续找下一条
(王七, 30)。- 回表,取整行,返回给 Server。
-
Server 层 判断:
age是 20 吗?- 不是,丢弃。
结果: 进行了 3 次回表,Server 层做了 3 次判断,最后只得到了 1 条数据。做了很多无用功(多回了 2 次表)。
✅ 阶段二:开启 ICP (MySQL 5.6 及以后)
MySQL 意识到:“嘿,InnoDB 兄弟,虽然你正在扫描索引,但我需要的 age 其实就在你手里的索引节点上。你能不能顺便帮我看一眼?如果 age 不对,你就别回表了,直接看下一个。”
这就是 Index Condition Pushdown:把 age = 20 这个条件下推到存储引擎层。
执行流程:
-
Server 层告诉 InnoDB:“给我找
name LIKE '王%'的记录,同时,如果age不等于 20,你就别给我了。” -
InnoDB 在索引树上找到第一条
(王五, 10)。-
InnoDB 直接检查索引上的值:
age是 10。 -
不符合
age = 20。 -
InnoDB 直接跳过(不回表,不返回给 Server)。
-
-
InnoDB 继续找下一条
(王六, 20)。-
检查索引:
age是 20。 -
符合!
-
InnoDB 拿着 ID: 2 回表,取出整行数据,返回给 Server。
-
-
Server 层 再次确认(兜底),保留数据。
-
InnoDB 继续找下一条
(王七, 30)。-
检查索引:
age是 30。 -
不符合,直接跳过。
-
结果: 只进行了 1 次回表。I/O 操作大幅减少,性能提升。
| 特性 | 判断 age=20 的位置 | 处理 (王五, 10) | 处理 (王六, 20) | 处理 (王七, 30) | 总回表次数 |
|---|---|---|---|---|---|
| 无 ICP | Server 层 (回表之后) | 回表 -> 丢弃 | 回表 -> 保留 | 回表 -> 丢弃 | 3 次 (慢) |
| 有 ICP | 存储引擎层 (回表之前) | 索引层直接丢弃 | 回表 -> 保留 | 索引层直接丢弃 | 1 次 (快) |
怎么看有没有用到 ICP?
你可以使用 EXPLAIN 命令查看执行计划。
|
|
-
如果输出的 Extra 列中包含:
Using index condition -
这就说明 ICP 生效了。
(注:如果 Extra 是 Using where,说明在 Server 层过滤;如果是 Using index,说明是覆盖索引,不需要回表,性能更好)
正常的联合索引(完美匹配)
假设索引还是 (name, age)。 SQL: SELECT * FROM user WHERE name = '王五' AND age = 20;
在这种情况下,都是等值查询,符合最左前缀原则。
-
怎么执行? InnoDB 里的 B+ 树是严格排序的:先按
name排,name此时固定是 ‘王五’,那么里面的数据就是严格按age排序的。 InnoDB 不需要“先找王五,再遍历过滤 age”,而是直接根据 B+ 树的算法,一次性跳(Seek) 到(王五, 20)这个节点的位置。 -
谁在做? 存储引擎 (InnoDB)。它利用 B+ 树结构直接定位数据。
-
Server 层在干嘛? Server 层只是给 InnoDB 下达了一个指令:“把
name='王五' AND age=20的数据给我。” InnoDB 说:“好的,我通过索引直接定位到了,这是数据。” Server 层拿到数据,甚至不需要再判断一次(但在代码实现逻辑上可能会做双重确认),直接发给客户端。
索引下推 ICP(范围查询导致断档)
这是我们刚才聊的场景。 SQL: SELECT * FROM user WHERE name LIKE '王%' AND age = 20;
-
怎么执行? 因为
name是范围,B+ 树只能帮你定位到“姓王的开始了”和“姓王的结束了”。在这个范围内,age是乱序的(相对全局而言)。 InnoDB 不能直接跳到age=20的位置,只能从“王”的第一个数据开始扫描。 -
ICP 的作用: 在扫描过程中,InnoDB 顺便看一眼索引里的
age。如果不符合,就不回表了。 -
谁在做? 还是 存储引擎 (InnoDB)。但是这次它不是“直接定位”,而是“扫描 + 顺便过滤”。
Server层处理“无法下推”的条件
这是 Server 层更重要的工作。如果 SQL 中包含不在索引里的字段条件,InnoDB 是无能为力的,必须由 Server 层来做。
举个例子:
-
索引:
(name, age) -
SQL:
1 2 3 4SELECT * FROM user WHERE name LIKE '王%' -- 索引前缀(用于范围扫描) AND age = 20 -- 索引下推(ICP 在 InnoDB 过滤) AND address = '北京'; -- 索引里没有(Server 层过滤)
详情见下方流程
索引下推查询的全流程
场景设定
-
表结构:
user (id, name, age, address) -
索引:
idx_name_age (name, age)—— 联合二级索引 -
SQL 语句:
-
1 2 3 4SELECT * FROM user WHERE name LIKE '王%' -- 索引范围查询 (Range) AND age = 20 -- 索引下推过滤 (ICP) AND address = '北京'; -- 普通条件 (Server 层过滤)
2. 详细执行流程 (Pipeline)
这个流程就像一个漏斗,每经过一层,数据就变少一点,性能就越高。
第一步:Server 层(准备阶段)
-
解析与优化: MySQL 优化器分析 SQL,发现可以使用
idx_name_age索引。 -
生成计划: 虽然
name是范围查询导致age无法用于定位,但优化器决定开启 ICP。- 标志: EXPLAIN 中的 Extra 显示
Using index condition。
- 标志: EXPLAIN 中的 Extra 显示
-
下发指令: Server 层告诉 InnoDB:“去
idx_name_age索引里找name以 ‘王’ 开头的数据。同时,把age = 20这个条件带上,如果不满足就别给我了。”
第二步:InnoDB 存储引擎层(ICP 核心阶段)
-
定位游标: InnoDB 在二级索引 B+ 树上,找到第一个
name匹配'王%'的叶子节点记录(假设是王五, 10岁, ID:1)。 -
索引内过滤 (ICP Check):
-
InnoDB 不急着回表。
-
它先看手头索引元组里的
age。 -
情况 A(不匹配): 发现
age是 10(不等于 20)。- 动作: 直接忽略该条记录,指针移向下一条。(省下一次回表 I/O)
-
情况 B(匹配): 指针移向下一条(假设是
王六, 20岁, ID:2)。- 检查
age是 20。符合条件!准备回表。
- 检查
-
第三步:InnoDB 存储引擎层(回表阶段)
-
读取主键: 拿到符合 ICP 条件的记录的主键
ID:2。 -
回表 (Table Lookup): 拿着
ID:2去**聚簇索引(主键索引)**树里查找。 -
提取行数据: 从聚簇索引叶子节点里读取完整的行数据(包含
name, age, address等所有列)。 -
返回数据: 把这行完整数据返回给 Server 层。
第四步:Server 层(最终兜底阶段)
-
接收数据: Server 层拿到
王六的完整行数据。 -
二次确认 (Double Check): 尽管 InnoDB 过滤过,Server 层依然会校验
name LIKE '王%'和age = 20(流程规范)。 -
补充过滤: Server 层检查 SQL 中剩下的、没法下推的条件 ——
address = '北京'。-
如果
王六的 address 是 ‘上海’ -> 丢弃。 -
如果
王六的 address 是 ‘北京’ -> 放入结果集。
-
-
发送结果: 将最终通过的记录发送给客户端。
3. 流程总结图解
| 步骤 | 所在层级 | 处理内容 | 数据状态 (示例) | 关键作用 |
|---|---|---|---|---|
| 1 | Server | 生成执行计划 | 指令:Scan idx, Filter age=20 |
开启 ICP |
| 2 | InnoDB | 扫描二级索引 | (王五, 10) -> ❌ 直接丢弃(王六, 20) -> ✅ 保留 |
ICP 核心:减少回表 |
| 3 | InnoDB | 回表 (聚簇索引) | 拿 ID:2 去找完整行数据 | 最耗时的 I/O 操作 |
| 4 | Server | 最终过滤 | 检查 address='北京' |
处理非索引列逻辑 |
PriorityQueue的相关API
| 操作 | 复杂度 (Time Complexity) | 备注 |
|---|---|---|
offer() / add() |
$O(\log N)$ | 插入操作,需要维护堆的属性。 |
poll() / remove() |
$O(\log N)$ | 移除最小/最大元素,需要重新堆化。 |
peek() / element() |
$O(1)$ | 仅查看堆顶元素。 |
remove(Object o) |
$O(N)$ | 移除任意元素,需要线性搜索。 |
| 方法 | 签名 | 描述 |
|---|---|---|
int size() |
public int size() |
返回队列中元素的数量。 |
void clear() |
public void clear() |
移除队列中的所有元素。 |
boolean isEmpty() |
public boolean isEmpty() |
如果队列不包含任何元素,则返回 true。 |
Comparator<? super E> comparator() |
public Comparator<? super E> comparator() |
返回用于对此队列中元素进行排序的比较器,或者返回 null(如果使用自然顺序)。 |
Object[] toArray() |
public Object[] toArray() |
返回包含队列中所有元素的数组。注意:返回的数组不保证是排序的。 |